Posters from 1st BayLDS-Day
The first BayLDS-Day took place on february 10th 2023 in Thurnau. Attached you find information from the different groups and details of their research.
- A Secure Web Application for Evaluating the Safety and Effectiveness of the AI Clinician in Predicting Treatment Dosage for Septic PatientsHide
-
A Secure Web Application for Evaluating the Safety and Effectiveness of the AI Clinician in Predicting Treatment Dosage for Septic Patients
Qamar El Kotob, Matthieu Komorowski, Aldo Faisal
Sepsis is a life-threatening condition that can result from infection and is characterised by inflammation throughout the body. General guidelines are in place for sepsis management but finding optimal doses for individual patients remains a challenge. The use of AI-based decision support systems has the potential to improve patient outcomes and reduce the burden on healthcare providers. Our research group has developed the AI Clinician, an AI model that predicts personalised dosages of vasopressors and fluids for septic patients in ICU. This model, based on lab results, vital signs, and treatment history, has shown promising results in its ability to accurately forecast dosages. In order to further evaluate the performance of the AI Clinician and assess its accuracy, reliability, as well as its potential to improve patient outcomes, a secure web application was created. This user-friendly and intuitive application enables clinicians to access patient information and the AI’s recommendations. By using the web application, we aim to gain a better understanding of the strengths and limitations of the AI Clinician, as well as its potential to improve patient outcomes in real-world clinical settings. In addition to evaluating the AI Clinician, we aim for the application to serve as a tool to support clinicians and help them be more efficient in their decision making. Through this study, we provide valuable insights into the potential of AI to support clinical decision making in the management of sepsis, while refining a system that could serve as a model for similar projects in the future.
- AI in higher education: DABALUGA - Data-based Learning Support Assistant to support the individual study processHide
-
AI in higher education: DABALUGA - Data-based Learning Support Assistant to support the individual study process
Prof. Dr. Torsten Eymann, Christoph Koch, Prof. Dr. Sebastian Schanz, PD Dr. Frank Meyer, Max Mayer M.Sc., Robin Weidlich, Dr. Matthias Jahn
The DABALUGA project aims to support the individual study process through a "digital mentor". Through small-step data collection and analysis during the learning process, difficulties and obstacles are to be identified at an early stage. The data-bases learning support assistant DABALUGA shall give hints to students and thereby reducing the students drop-out rate.
Since 2014, the University of Bayreuth has been organizing the Student Life Cycle with an innovative, data-based Campus Management System (CMS) with various implemented interfaces. The study-related data collected in the CMS and learning management system (LMS) during studies can provide better insights into learning processes. Tasks in the LMS (MOODLE/elearning) must be didactically planned and structured in such a way that the learning process can be captured using AI. Students are contacted and informed directly (with SCRIT). Additional data collection (e.g. about learning type and learning motivation) and evaluation in accordance with data protection regulations is necessary, even if all supervision is voluntary.
AI and historical data analysis (data from previous terms) make it possible to divide large student groups into clusters and to give specific hints. Teaching should respond to students' difficulties and needs at short notice. Thus, the data-based learning support assistant DABALUGA contributes to the improvement of the quality in higher education. - AI in Higher Education: Developing an AI Curriculum for Business & Economics Students Hide
-
AI in Higher Education: Developing an AI Curriculum for Business & Economics Students
Torsten Eymann, Peter Hofmann, Agnes Koschmider, Luis Lämmermann, Fabian Richter, Yorck Zisgen
The deployment of AI in business requires specific competencies. In addition to technical expertise, the business sphere requires specific knowledge of how to evaluate technical systems, embed them in processes, working environments, products and services, and to manage them continuously. This bridge-building role falls primarily to economists as key decision-makers. The target group of the joint project, therefore, encompasses business administration and related (business informatics, buisiness engineering, etc.), which make up a total of approx. 22 % of students. The goal of the joint project is the development and provision of a teaching module kit for AI, that which conveys interdisciplinary AI skills to business students in a scientifically well-founded and practical manner. The modular teaching kit supports teaching for Bachelor's, Master's, Executive Master's students, and doctoral students at universities and universities of applied sciences (UAS). It comprises three elements: (1) AI-related teaching content, which conforms to the background, skills, and interests of the students as well as career-relevant requirements. Therefore, high-quality teaching content is being created and established as Open Education Resources (OER). (2) In the AI training factory, AI content will be developed in collaboration with students in a hands-on manner. (3) An organizational and technical networking platform is being created on which universities, industrial partners, and students can network. The joint project brings together eleven professorships from three universities and one UAS from three German states, who are united in promoting AI competencies among students of economics and business administration. Content and teaching modules are jointly developed, mutually used, and made available to the public. Compared to individual production, this strengthens the range and depth of the offer as well as the efficiency and quality of teaching.
- AI in Higher Education: Smart Sustainability Simulation GameHide
-
AI in Higher Education: Smart Sustainability Simulation Game
Torsten Eymann, Katharina Breiter
Smart Sustainability Simulation Game (S3G) is a student-centered, interactive simulation game with teamwork, gamification, and competition elements. The goal is to create a student-centered and didactically high-quality teaching offer that conveys techno-economic competencies in the context of digitalization and transformation of industrial value chains towards sustainability. The course will be offered in business administration and computer science programs at the participating universities, continued after the end of the project, and made available to other users (OER). Accordingly, the target group consists of master's students of business administration, computer science and courses at the interface (e.g., business and information systems engineering, industrial engineering, digitalization & entrepreneurship). Students learn in interdisciplinary, cross-university groups and find themselves in simulated practical situations in which they contribute and expand their competencies. Particular attention is paid to creating authentic challenge situations in a communication-oriented environment, teamwork, continuous feedback, and the opportunity to experiment. Based on four cases of an industrial value chain in the context of e-mobility, students work through various techno-economic questions relating to data management, data analytics, machine learning, value-oriented corporate decisions, sustainability decisions, strategic management, and data-based business models as realistically and hands-on as possible. For each case, the technical feasibility, economic sense, and sustainability impacts (ecological, social, and economic) are considered. In the sense of problem-based learning, students find solutions to the given problem largely on their own. Teachers merely act in a supporting role.
The project is funded by the "Stiftung Innovation in der Hochschullehre" and is being worked on and carried out jointly by the University of Bayreuth (Prof. Dr. Torsten Eymann), the University of Hohenheim (Prof. Dr. Henner Gimpel) and Augsburg University of Applied Sciences (Prof. Dr. Björn Häckel). The course offering will be carried out for the first time in the summer term 2023.
- Analysing Electrical Fingerprints for Process OptimizationHide
-
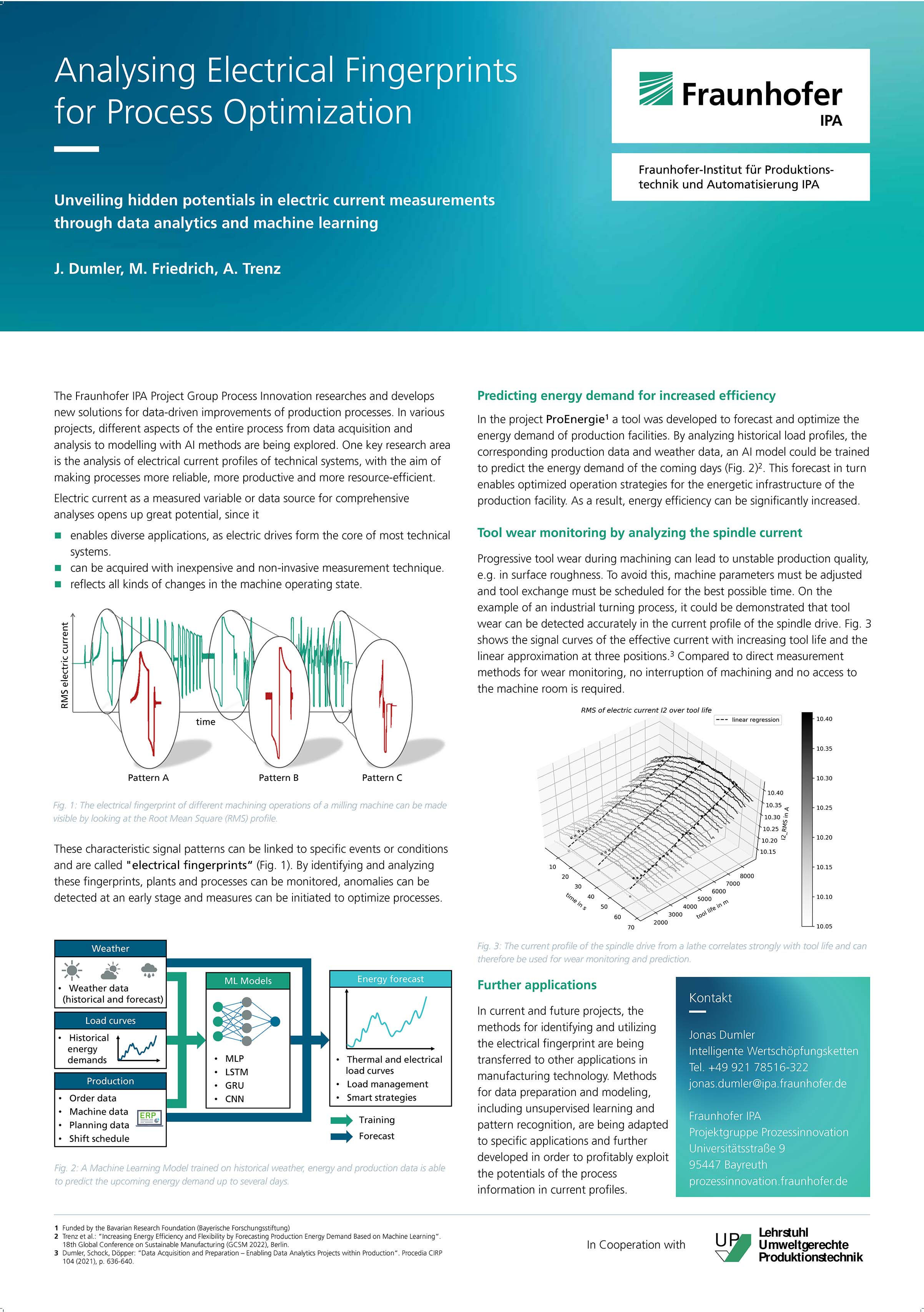

Analysing Electrical Fingerprints for Process Optimization
Jonas Dumler, Markus Friedrich, André Trenz
The Fraunhofer IPA Project Group Process Innovation researches and develops new solutions for the data-driven improvement of production processes. In the research, we consider the entire process from data acquisition and analysis to modelling with machine learning methods. One focus is the analysis of electrical current profiles of technical systems, with the aim of making processes more reliable, more productive and more resource-efficient.
Electric current as a measured variable or data source for comprehensive analyses opens up great potential, as electric drives are at the heart of many technical systems. Moreover, electrical power consumption can be measured using comparatively inexpensive measurement technology and with little installation effort. Different operating states of a machine or a drive are reflected in characteristic signal features, the "electrical fingerprint". By identifying and analysing these characteristics, plants and processes can be monitored, anomalies can be detected at an early stage and suitable measures can be initiated to optimise processes.
Two recent success stories illustrate the possibilities:
1) By analysing historical consumption data of production lines and the associated order data as well as information about the respective weather at the time, it was possible to develop a machine learning model to forecast the energy consumption of the upcoming days. This forecast in turn enables optimised planning of the energy use for the entire building infrastructure of the production facility. As a result, energy efficiency can be significantly increased.
2) In measured current profile of the spindle motor of a CNC milling machine, tool wear can be detected at an early stage so that the optimal timing for a tool change can be predicted. The data acquisition can be done without intervening in the machine room and without interrupting the machining process. - Anchoring as a Structural Bias of Group DeliberationHide
-
Anchoring as a Structural Bias of Group Deliberation
Sebastian Braun, Soroush Rafiee Rad, Olivier Roy
We study the anchoring effect in a computational model of group deliberation on preference rankings. Anchoring is a form of path-dependence through which the opinions of those who speak early have a stronger influence on the outcome of deliberation than the opinions of those who speak later. We show that anchoring can occur even among fully rational agents. We then compare the respective effects of anchoring and three other determinants of the deliberative outcome: the relative weight or social influence of the speakers, the popularity of a given speaker's opinion, and the homogeneity of the group. We find that, on average, anchoring has the strongest effect among these. We finally show that anchoring is often correlated with increases in proximity to single-plateauedness. We conclude that anchoring can be seen as a structural bias that might hinder some of the otherwise positive effects of group deliberation.
- An explainable machine learning model for predicting the risk of hypoxic-ischemic encephalopathy in new-bornsHide
-
An explainable machine learning model for predicting the risk of hypoxic-ischemic encephalopathy in new-borns
Balasundaram Kadirvelu, Vaisakh Krishnan Pulappatta Azhakapath,Pallavi Muraleedharan, Sudhin Thayyil, Aldo Faisal
Background
Around three million babies (10 to 20 per 1000 live births) sustain birth-related brain injury (hypoxic-ischemic encephalopathy or HIE) in low and middle-income countries, particularly in Africa and South Asia every year. More than half of the survivors develop cerebral palsy and epilepsy contributing substantially to the burden of preventable early childhood neuro-disability. The risk of HIE could be substantially reduced by identifying the babies at risk based on the antenatal medical history of the mother and providing better care to the mother during delivery.Methods
As part of the world’s most extensive study on babies with brain injuries (Prevention of Epilepsy by reducing Neonatal Encephalopathy study), we collected data from 38,994 deliveries (750 being HIE) from 3 public maternity hospitals in India. We have developed an explainable machine-learning model (using a gradient-boosted ensemble approach) that can predict the risk of HIE from ante-natal data available at the time of labour room admission. The model is trained on a dataset of 205 antenatal variables (113 being categorical variables). We used a cost-sensitive learning technique and a balanced ensemble approach to handling the strong class imbalance (1:52).Results
The ensemble model achieved an AUC score of 0.7 and a balanced accuracy of 70% on the test data and fares far better than clinicians in making an HIE prediction. A SHAP framework was used to interpret the trained model by focusing on how salient factors affect the risk of HIE. A model trained on the 20 most important features is available as a web app at brainsaver.org.Conclusion
Our model relies on clinical predictors that may be determined before birth, and pregnant women at risk of HIE might be recognised earlier in childbirth using this approach. - An Optimal Control Approach to Human-Computer InteractionHide
-
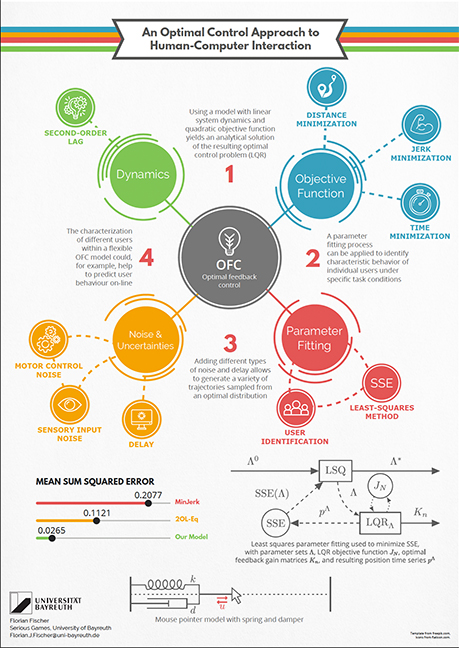
An Optimal Control Approach to Human-Computer Interaction
Florian Fischer, Markus Klar, Arthur Fleig, Jörg Müller
We explain how optimal feedback control (OFC), a theory used in the field of human motor control, can be applied to understanding Human-Computer Interaction.
We propose that the human body and computer dynamics can be interpreted as a single dynamical system. The system state is controlled by the user via muscle control signals, and estimated from sensory observations. We assume that humans aim at controlling their body optimally with respect to a task-dependent cost function, within the constraints imposed by body, environment, and task. Between-trial variability arises from signal-dependent control noise and observation noise.
Using the task of mouse pointing, we compare different models from optimal control theory and evaluate to what degree these models can replicate movements. For more complex tasks such as mid-air pointing in Virtual Reality (VR), we show how Deep Reinforcement Learning (DRL) methods can be leveraged to predict human movements in a full skeletal model of the upper extremity. Our proposed "User-in-the-Box" approach allows to learn muscle-actuated control policies for different movement-based tasks (e.g., target tracking or choice reaction), using customizable models of the user's biomechanics and perception.We conclude that combining OFC/DRL methods with a moment-by-moment simulation of the dynamics of the human body, physical input devices, and virtual objects, constitutes a powerful framework for evaluation, design, and engineering of future user interfaces.
- Application of ML models to enhance the sustainability of polymeric materials and processesHide
-
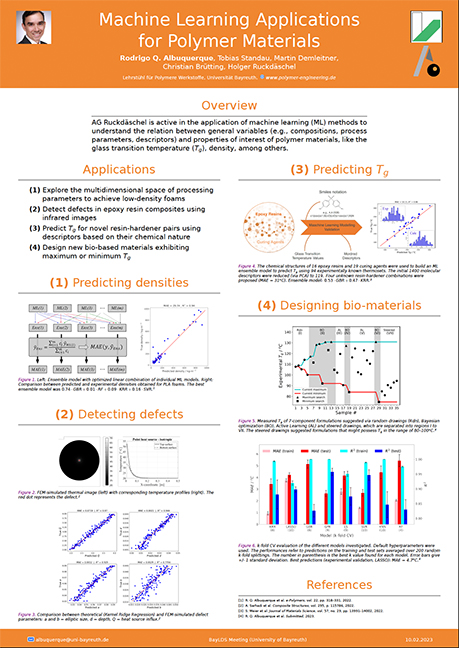
Application of ML models to enhance the sustainability of polymeric materials and processes
Rodrigo Q. Albuquerque, Tobias Standau, Christian Bruettting, Holger Ruckdaeschel
This work highlights some digitization activities in the Polymer Engineering Department related to the application of machine learning methods (ML) to predict properties of polymer materials and related processing parameters in their production. Training of supervised ML models (e.g., Gaussian processes, support vector machine, random forests) has been used to understand the relationships between general variables and various target properties of the systems under study. Understanding these relationships also aids in the intelligent development of novel materials and efficient processes, ultimately leading to improvements in the sustainability of the materials produced.
- ArchivalGossip.com. Digital Recovery of 19th-Century Tattle TalesHide
-
ArchivalGossip.com. Digital Recovery of 19th-Century Tattle Tales
Katrin Horn, Selina Foltinek
ArchivalGossip.com is the digital outlet of the American Studies research project “Economy and Epistemology of Gossip in Nineteenth-Century US American Culture” (2019-2022). Examining realist fiction, life writing, newspaper articles, and magazines, the project seeks to answer the questions of what and how gossip knows, and what this knowledge is worth. The digital part of the project collects letters, diaries, photographs and paintings, auto/biographies, and newspaper articles as well as information on people and events. Since gossip relies on networks, the project needs to store, sort, annotate, and visualize multiple documents, as well as illustrate their relation to each other. To this end, the team set up an Omeka database (ArchivalGossip.com/collection) that is freely available to the public and based on transcriptions and annotations of hundreds of primary sources from the nineteenth century. Additionally, we have built a WordPress website (ArchivalGossip.com) to add information on sources and archives to help contextualize our own research (bibliographies, annotation guidelines), and created blog posts to accompany the digital collections.
The database enables users to trace relations between people (e. g. “married to,” “friends with”) and references (e. g. “mentions,” “critical of,” “implies personal knowledge of”) in intuitive relationship-visualizations. The database and its diverse plugins furthermore facilitate work with different media formats and tracing relational agency of female actors in diverse ways: chronologically (timelines: Neatline Time), geospatially (Geolocation mapping tool), and according to research questions (exhibits, tags). The project furthermore uses DH tools such as Palladio to visualize historical data, for example, by providing graphs with different node sizes that display historical agents who participate in the exchange of correspondence. Metadata is collected according to Dublin Core Standards and additional, customized fields of item-type-specific information. Transcription of manuscript material is aided via the AI-supported tool Transkribus.
For more information, see: https://handbook.pubpub.org/pub/case-archival-gossip - Artificial intelligence as an aspect of computer science teaching in schoolsHide
-
Artificial intelligence as an aspect of computer science teaching in schools
Matthias Ehmann
We deal with artificial intelligence as part of computer science classes for schools. We develop teaching and learning scenarios for school students and teachers to impart artificial intelligence skills.
Artificial intelligence becomes a compulsory part of computer science classes for all students at Bavarian high schools this year. From March 2023, together with the State Ministry for Education and Culture, we will be running a three-year in-service training program for teachers at Bavarian high schools in order to qualify them professionally and didactically. As part of the training, we record and evaluate changes in teachers’ attitudes towards artificial intelligence.Since 2018 we have been conducting workshops for school students about artificial intelligence and autonomous driving at the TAO student research center. The students develop a basic understanding of artificial intelligence issues. They conduct their own experiments on decision-making with the k-nearest-neighbor method, artificial neurons and neural networks. They recognize the importance of data, data pre-processing and hyperparameters for the quality of artificial intelligence systems. They discuss opportunities, limits and risks of artificial intelligence.
We record and evaluate changes in attitudes of the participants towards artificial intelligence. - Bi-objective optimization to mitigate food quality losses in last-mile distributionHide
-

Bi-objective optimization to mitigate food quality losses in last-mile distribution
Christian Fikar
Food supply chain management is challenged by various uncertainties present in daily operations such as fluctuation in supply and demand as well as varying product qualities along production and logistics. Related processes are highly complex as various product characteristics need to be considered simultaneously to ship products from farm to fork on time and in the right quality. To contribute to a reduction in food waste and losses, this poster provides an overview of recent operations research activities of the Chair of Food Supply Chain Management in the context of last-mile deliveries of perishable food items. It introduces a bi-objective metaheuristic solution procedure to optimize home delivery of perishable food from stores to customers’ premises. A special focus is set on the consideration of quality aspects as well as on deriving strategies and implications to facilitate more sustainable operations in the future.
- Bioinformatics in plant defence researchHide
-
Bioinformatics in plant defence research
Anna Sommer1, Miriam Lenk2, Daniel Lang3, Claudia Knappe2, Marion Wenig2, Klaus F. X. Mayer3, A. Corina Vlot1
1University of Bayreuth, Faculty of Life Sciences: Food, Nutrition and Health, Chair of Crop Plant Genetics, Fritz-Hornschuch-Str. 13, 95326 Kulmbach, Germany.
2Helmholtz Zentrum München, Institute of Biochemical Plant Pathology, Neuherberg, Germany
3Helmholtz Zentrum München, Institute of Plant Genome and Systems Biology, Neuherberg, GermanyIn our group, we work on the genetic basis of systemic resistance in crop plants including wheat, barley, and tomato. To this end, we facilitate different computational analysis methods to evaluate changes, for example in gene expression patterns or microbiome composition. We work mainly on quantification and differential gene expression analysis of RNAseq data, working for example with DESeq2. While we have so far used commercial services, we aim to integrate quality control, pre-processing, and alignment of genes by utilizing FastQC, Bowtie2 or HISAT2 in our own data analysis pipeline. Regarding the microbiome of plants, we analyse 16S amplicon data utilizing Phyloseq as well as DESeq2.
In search of new plant immune regulators, we actively create plant mutants which are deficient in certain defence-associated genes via CRISPR/Cas9 genome editing. To improve this method, we evaluate mutation efficiency of CRISPR/Cas elements, in particular the guideRNA. To this end, we simulate secondary structures of guideRNA sequences and evaluate the complementarity between guideRNA and target sequences.
Monocotyledonous plants, including the staple crop wheat, present a specific challenge, since they have an especially large genome with over 17 Gb (five times the size of a human genome) and highly repetitive regions. In addition, the hexaploid chromosome set of wheat includes three subgenomes (each diploid) with more than 97% homology between the subgenomes, which adds its own particular challenges to working with these genomes.
Our overarching aim is to reduce the use of pesticides by strengthening the plans own defence mechanisms. To this end we aim to deepen our knowledge of plant signalling upon interaction with microbes, be it pathogenic or beneficial. - Biomechanical Simulations for Sport ProductsHide
-
Biomechanical Simulations for Sport Products
Michael Frisch, Tizian Scharl, Niko Nagengast
In the field of biomechanics and sports technology, simulation is a proven means of making predictions in the movement process or in product development.
On the one hand, software for modelling, simulating, controlling, and analysing the neuromusculoskeletal system is used at the Chair of Biomechanics to investigate possible muscular differences in different sports shoes. On the other hand, the process chain of virtual product development, consisting of computer-aided engineering (CAD), finite element analysis (FEA), structural optimisation and fatigue simulation, is used to find innovative solutions for sports products.For both digital methods, however, it is essential to carry out biomechanical analyses in advance using motion capturing, inertial measurement sensors and/or force measurement units, among other things, in order to record real boundary conditions and better understand motion sequences.
- Black holes, pulsations, and damping: a numerical analysis of relativistic galaxy dynamicsHide
-
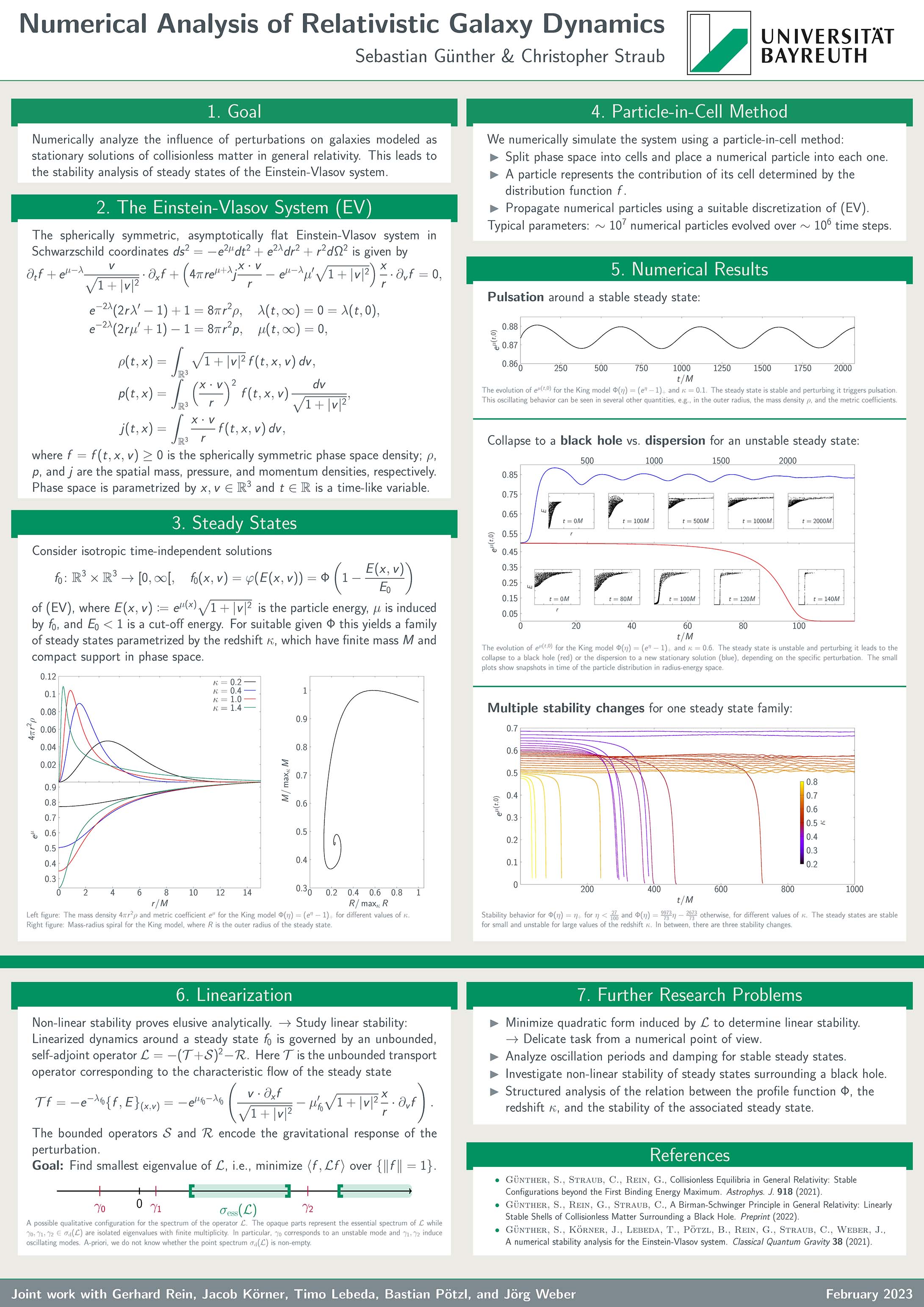
Black holes, pulsations, and damping: a numerical analysis of relativistic galaxy dynamics
Sebastian Günther, Christopher Straub
We analyse the dynamics of star clusters or galaxies modeled by the Einstein-Vlasov system, which describes the evolution of the phase space density function of the configuration.
Of particular interest is the stability behaviour of equilibria: We find that perturbing a steady state can lead to pulsations, damping, collapse to a black hole, or dispersion.
We numerically simulate various aspects of this system in order to verify the validity of mathematical hypotheses and to develop new ones.
Firstly, we use a particle-in-cell method to determine the non-linear stability of equilibria numerically and find that it behaves differently then previously thought in the literature.
Secondly, the spectral properties of the steady states are of interest in order to find oscillating and exponentially growing modes. This leads to a difficult optimization problem of an unbounded operator.
In both of these numerical issues, we mainly rely on "brute-force" algorithms which probably allow for a lot of improvement. - Blaming the Butler? - Consumer Responses to Service Failures of Smart Voice-Interaction TechnologiesHide
-
Blaming the Butler? - Consumer Responses to Service Failures of Smart Voice-Interaction Technologies
Timo Koch, Dr. Jonas Föhr, Prof. Dr. Claas Christian Germelmann
Marketing research has consistently demonstrated consumers’ tendency to attribute human-like roles to smart voice-interaction technologies (SVIT) (Novak and Hoffman 2019; Schweitzer 2019; Foehr and Germelmann 2020). However, smart service research has largely ignored the effect of such role attributions on service evaluations (Choi et al. 2021). Hence, we explore, how (failed) service encounters with SVIT affect consumers’ service satisfaction and usage intentions when role attributions are considered. Understanding such effects can help marketers to design more purposeful smart services.
We conducted a series of two scenario-based online experiments employing a Wizard of Oz approach. Thus, we manipulated role attribution by semantic priming in the first and by verbal priming in the second study and differentiated between a successful service, a mild, and a strong service failure. In the scenarios, consumers engaged in fictitious service encounters with SVIT, in which they vocally commanded the SVIT what to do whereas the SVIT answered verbally. A pretest in each study confirmed the success of our manipulations so that the tested scenarios could be employed in our main studies.
The results show that service failures significantly affected both consumers’ service satisfaction and usage intention. Nevertheless, we found contrary results to previous studies regarding the moderating influence of role attributions. Thus, we found preliminary evidence that service failures by SVITs are more likely to be excused if SVITs are construed as masters, and not as servants. However, strong manipulation was needed to let the consumers perceive the SVIT as a master or as a servant. Hence, future research should examine under which conditions consumers are affected by different role attributions to SVIT.
- Collective variables in complex systems: from molecular dynamics to agent-based models and fluid dynamicsHide
-
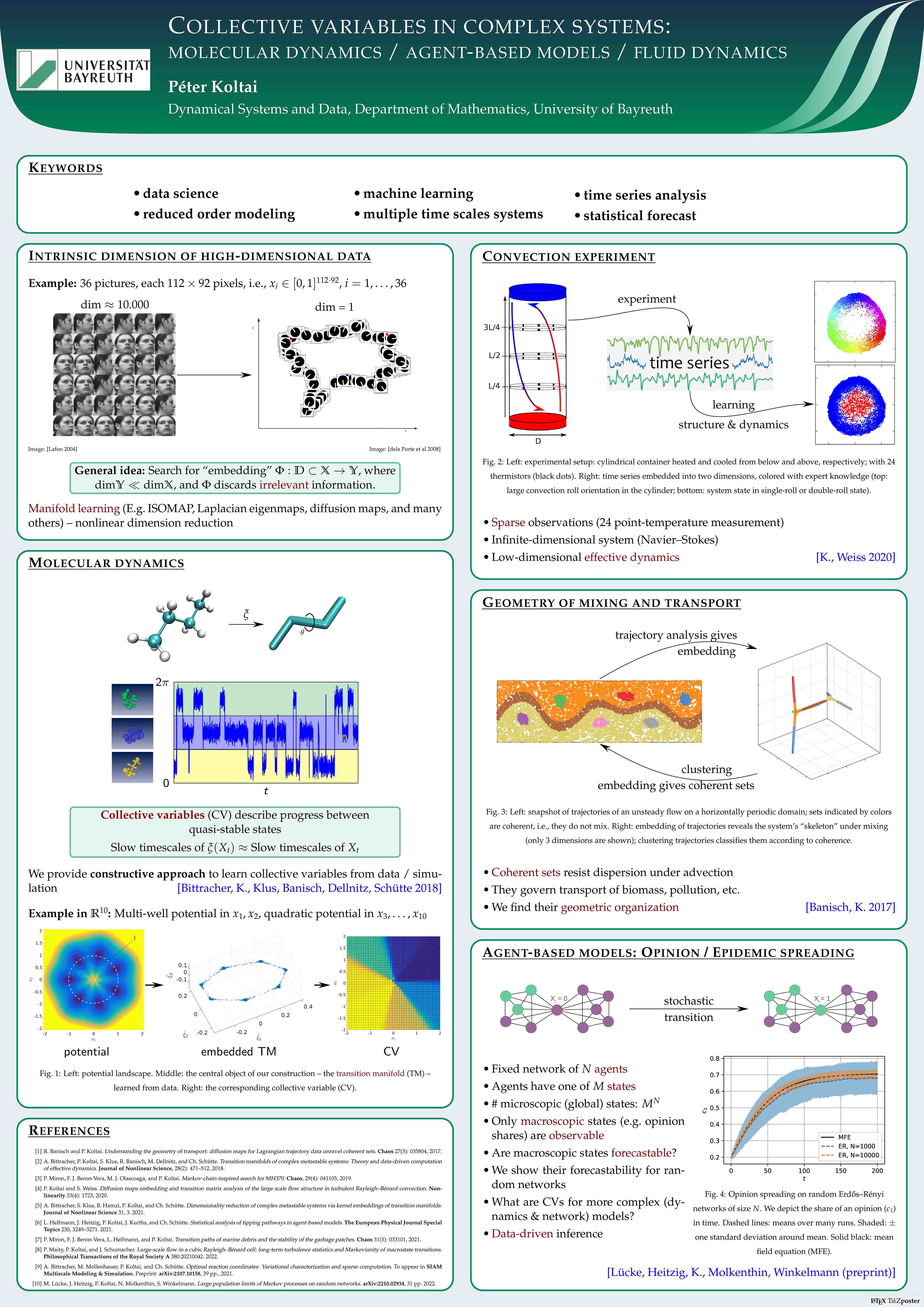
Collective variables in complex systems: from molecular dynamics to agent-based models and fluid dynamics
Péter Koltai
The research of the Chair for Dynamical Systems and Data focuses on the data-driven analysis and forecast of complex (dynamical) systems. One particular aspect is reduced order modeling of such systems by developing new tools on the interface of dynamical systems, machine learning and data science. This presentation summarizes some recent projects in this direction, with various application across different scientific fields:
The identification of persistent forecastable structures in complicated or high-dimensional dynamics is vital for a robust prediction (or manipulation) of such systems in a potentially sparse-data setting. Such structures can be intimately related to so-called collective variables known for instance from statistical physics. We have recently developed a first data-driven technique to find provably good collective variables in molecular systems. Here we will discuss how the concept generalizes to other applications as well, such as fluid dynamics and social or epidemic dynamics.
- Computer Vision for automated tool wear monitoring and classificationHide
-
Computer Vision for automated tool wear monitoring and classification
Markus Friedrich, Theresa Gerber, Jonas Dumler, Frank Döpper
In the manufacturing industry, one of the biggest tasks is to act in the sense of sustainability and to avoid the waste of resources. In this sense, there is great potential in reducing the renewal of production tools by optimizing replacement intervals. Especially in the field of machining, tools are often replaced according to fixed intervals or empirically determined intervals, regardless of actual wear. Thus, the need arises for a way to efficiently monitor the wear condition and predict the remaining life of tools.
A system for automatic monitoring and classification of the wear of face milling tools was developed at the chair. A direct method in the form of optical monitoring was used. Due to advances in camera technology and artificial intelligence, excellent results could be achieved by using a computer vision approach without resorting to expensive camera technology. Due to the compact design, both online and offline operation are possible. The use of low-cost camera technology and an efficient algorithm allow the retrofitting into existing machines and is therefore also attractive for small and medium-sized enterprises.
- Constraint-based construction of geometric representationsHide
-
Constraint-based construction of geometric representations
Andreas Walter
My research related to my PhD thesis in the field of mathematics and computer science relates to the optimization of equations representing geometric systems. The software sketchometry (www.sketchometry.org) offers a simple tool for creating geometric constructions with your finger or mouse. These constructions are built up hierarchically, as with analog constructions. This means that certain construction steps have to happen before others in order to create the finished construction. The constraint-based geometry approach follows a different procedure. Here the user has a given set of generic objects that he can restrict with constraints. These constraints can be understood as equations whose system has to be optimized in an efficient way within a certain framework. The runtime of the algorithm in particular plays a central role here.
The goal of my project is a software that is constraint-based in design, but is as easy to use as sketchometry. If the user changes his construction after defining the constraints, for example by dragging a point, the constraints should continue to be fulfilled. The optimization required for this does not yet have the desired performance. - Context-Aware Social Network AnalysisHide
-
Context-Aware Social Network Analysis
Mirco Schönfeld, Jürgen Pfeffer
We are surrounded by networks. Often we are part of these networks ourselves, for example with our personal relationships. Often the networks are not visible per se, for example because the structures first have to be extracted from other data to be accessible.
Regardless of the domains from which the networks originate, structural information is only one part of the model of reality: each network, each node, and each connection within are subject to highly individual contextual circumstances. Such contextual information contains rich knowledge. They can enrich the structural data with explanations and provide access to semantics of structural connections.
This contrasts with the classical methods of network analysis, which indeed produce easily accessible and easily understandable results. But, so far, little attention can be payed to contextual information. This contextual information has yet to be made accessible to algorithms of network analysis.
This talk therefore presents methods for processing contextual information in network analysis using small and big data as examples. On the level of manageable data sets, for example, new types of centrality rankings can be derived. Here, context introduces possible constraints and acts as an inhibitor for the detection of paths. Consequently, individual views of single nodes on the global network emerge.
On the level of very large data sets, the analysis of contextually attributed networks offers new approaches in the field of network embedding. The resulting embeddings contain valuable information about the semantics of relationships.
The goal of context-aware social network analysis is, on the one hand, to benefit from the diverse knowledge that lies dormant in contextual information. On the other hand, novel explanations for analysis results are to be opened up and made accessible.
- Data-derived digital twins for the discovery of the link between shopping behaviour and cancer riskHide
-
Data-derived digital twins for the discovery of the link between shopping behaviour and cancer risk
Fabio S Ferreira, Suniyah Minhas, James M Flanagan, Aldo Faisal
Early cancer prevention and diagnostics are typically based on clinical data, however behavioural data, especially consumer choices, may be informative in many clinical settings. For instance, changes in purchasing behaviour, such as an increase in self-medication to treat symptoms without understanding the root cause, may provide an opportunity to assess the person’s risk of developing cancer. In this study, we used probabilistic machine learning methods to identify data-derived Digital Twins of patients' behaviour (i.e., latent variable models) to investigate novel behavioural indicators of risk of developing cancer, discoverable in mass transactional data for ovarian cancer, for which it is known that non-specific or non-alarming symptoms are present, and are thus likely to affect purchasing behaviour. We applied Latent Dirichlet Allocation (LDA) to the shopping baskets of loyalty shopping card data of ovarian cancer patients with over two billion anonymised transactional logs to infer topics (i.e., topics) that may describe distinct consumers’ shopping behaviours. This latent continuous representation (the Digital Twin) of the patient can then be used to detect changepoints that may indicate early diagnosis, and therefore increase a patient’s chances of survival. In this study, we compared two machine learning models to identify changepoints on synthetic data and ovarian cancer data: the Online Bayesian Changepoint detector (unsupervised method) and a Long Short-Term Memory (LSTM) network (supervised method). Our approaches showed good performance in identifying changepoints in artificial shopping baskets, and promising results in the ovarian cancer dataset, where future work is needed to account for potential external confounders and the limited sample size.
- Deep Learning in BCI DecodingHide
-
Deep Learning in BCI Decoding
Xiaoxi Wei
Deep learning has been successful in BCI decoding. However, it is very data-hungry and requires pooling data from multiple sources. EEG data from various sources decrease the decoding performance due to negative transfer. Recently, transfer learning for EEG decoding has been suggested as a remedy and become subject to recent BCI competitions (e.g. BEETL), but there are two complications in combining data from many subjects. First, privacy is not protected as highly personal brain data needs to be shared (and copied across increasingly tight information governance boundaries). Moreover, BCI data are collected from different sources and are often based on different BCI tasks, which has been thought to limit their reusability. Here, we demonstrate a federated deep transfer learn- ing technique, the Multi-dataset Federated Separate-Common- Separate Network (MF-SCSN) based on our previous work of SCSN, which integrates privacy-preserving properties into deep transfer learning to utilise data sets with different tasks. This framework trains a BCI decoder using different source data sets obtained from different imagery tasks (e.g. some data sets with hands and feet, vs others with single hands and tongue, etc). Therefore, by introducing privacy-preserving transfer learning techniques, we unlock the reusability and scalability of existing BCI data sets. We evaluated our federated transfer learning method on the NeurIPS 2021 BEETL competition BCI task. The proposed architecture outperformed the baseline decoder by 3%. Moreover, compared with the baseline and other transfer learning algorithms, our method protects the privacy of the brain data from different data centres.
- Digital data ecosystems for the verification of corporate carbon emission reportingHide
-

Digital data ecosystems for the verification of corporate carbon emission reporting
Marc-Fabian Körner, Jens Strüker
Carbon taxes and emission trading systems have proven to be powerful decarbonization instruments; however, achieving our climate goals requires to reduce emissions drastically. Consequently, the EU has adopted regulatory measures, e.g., the expansion of the ETS or the carbon border adjustment mechanism (CBAM), which will require carbon emissions to be managed and priced more precisely. However, this capability is accompanied by unprecedented challenges for companies to report their carbon emissions in a more fine-granular and verifiable manner. These requirements call for an integrated and interoperable systems that can track carbon emissions from cradle to grave by enabling a digital end-to-end monitoring, reporting, and verification tooling (d-MRV) of carbon emissions across value chains to different emitters. To establish such systems, our research proposes recent advances in digital science as central key-enablers. In detail, our research aims to design digital data ecosystems for the verification of corporate carbon emission reporting that accounts for regulatory requirements (cf. CBAM and EU-ETS) and that prevents greenwashing and the misuse of carbon labels that are currently highly based on estimations. Accordingly, it will be possible to digitally verify and report a company’s – and even a specific product’s – carbon footprint. Therefore, we apply several digital technologies that fulfill different functions to enable digital verification: While distributed ledger technologies, like Blockchains, may be used as transparent registers – not for the initial data but for the proof of correctness of inserted data – zero-knowledge proofs and federated learning may be applied for the privacy-preserving processing of competition-relevant data. Moreover, a digital identity management may be used for the identification of machines or companies and for governance and access management. Against this background, we also refer to data spaces as corresponding reference architectures. Overall, we aim to develop end-to-end d-MRV solutions that are directly connected to registries and the underlying infrastructure.
- Digital Science in Business Process ManagementHide
-
Digital Science in Business Process Management
Maximilian Röglinger, Tobias Fehrer, Dominik Fischer, Fabian König, Linda Moder, Sebastian Schmid
Business Process Management (BPM) is concerned with the organization of work in business processes. To this end, processes are defined, modelled, and continuously analysed and improved. With the increasing digitization and system support of process execution in recent years, new opportunities for applying novel data-driven BPM methods for process analysis and improvement have emerged. Research in this field aims to gain insight from process execution data and translate it into actionable knowledge. On the insight perspective, our research focuses on how to extract process behaviours from semi-structured and unstructured data such as videos or raw sensor data, and applies machine learning to detect patterns in workflows. In addition, we apply generative machine learning techniques to improve the data quality of raw data from process execution for subsequent analysis. Another example is the application of natural language processing techniques for this purpose. Focusing on the conversion from insight into action, experts are increasingly using this data for analyses with the help of process mining. In knowledge- and creativity-intensive projects, process improvement options are then derived and evaluated for their value. In our research, we have explored approaches to support the search for better process models through technology: In an assisted approach, we automatically search for process improvement ideas and compare different redesign options via simulation experiments, so that users are supported in their decision making. In another approach, we use Generative Adversarial Networks to propose entirely new process models and stimulate human creativity. Through this selection of work, it becomes apparent that BPM can benefit in many ways from digital technologies and, therefore, there are still numerous opportunities to explore.
- Digital Science in histological analysisHide
-

Digital Science in histological analysis
Janin Henkel-Oberlaender, Eda Bedir, Chenyan Zheng, Brit-Maren Schjeide
Category c: showcase research where authors have not yet “digitised” the research but are keen on finding collaborators for it.
Immunohistochemistry and Immunofluorescence are widely used methods in (patho)biochemistry and (patho)physiology to investigate the general morphology as well as the expression pattern of specific proteins in animal and human tissues. Antigens will be tagged with specific antibody-antibody reactions, which can be visualized by chromogens or fluorophores in high-resolution microscopy. As a result, different staining pattern can be visualized in microscopical images. While an all-or-nothing-signal is easy to quantify but rare, scientists are often faced with the problem that the analysis shows “just” different distribution patterns of the signal within the tissue slide. As an example, regular staining of individual macrophages, which are detected by a specific surface protein antibody, in liver tissue is normal. But accumulation of these immune cells in one localization in the tissue is pathological, although the total amount of staining signal is similar. In this case, several manual steps are necessary for quantification, and this makes the evaluation process less objective.
Digital Science might be able to (partly) solve this problem and will open new possibilities to a fast and objective evaluation of expression pattern of specific structures in histological tissue analysis. - Digitization of Product Development and RecyclingHide
-
Digitization of Product Development and Recycling
Niko Nagengast, Franz Konstantin Fuss
Digitization and automation can accelerate the value creation of performance, cost, and sustainability. During all phases of a product’s Life Cycle, algorithmic techniques can be applied to create, optimize and evaluate products or processes. With the technological and commercial maturity of Additive Manufacturing, an extension of design and material opportunities can be explored and lead towards potentials of innovation in all sectors of the industry. A fusion of both generates a rethinking of material search and substitution, a different geometrical approach of design, and various possibilities in manufacturing.
In considerations of the magnitude of freeform geometries, a time-wise short-term implementation of new materials (relative to other fields), a strive towards lightweight products, and a flexible prototype-like character, the sport and sport-medical industry seems quite promising to set benchmarks or proof-of-concepts regarding innovative workflows: digital concept and detail design, fabrication, reengineering, evaluation, and decision making.
The proposed work contains a cross-section of case studies and concepts to combine digital approaches reaching from parametric form-finding opportunities of surfboard fins, a material modelling approach towards sustainable and anisotropic product design using Fused Filament Fabrication (FFF), a guideline approach for the substitution of conventional parts through AM using multi-criteria-decision making, and a KI-driven, databased search flow for a sustainable material implementation.The outcome clearly shows the potential to entwine various algorithmic designs with AM. Furthermore, it shall inspire others to implement and scale these or more profound strategies in their academical or industrial field of expertise.
- Discovery Space: An AI-Enhanced Classroom for Deeper Learning in STEMHide
-
Discovery Space: An AI-Enhanced Classroom for Deeper Learning in STEM
Franz X. Bogner, Catherine Conradty
Traditional assessments of cognitive skills and knowledge acquisition are in place in most educational systems. These approaches though are not harmonized with the innovative and multidisciplinary curricula proposed by current reforms focusing on the development of 21st century skills that require in-depth understanding and authentic application. This divergence must be addressed if STEM education is to become a fulfilling learning experience and an essential part of the core education paradigm everywhere. Discovery Space based on rooted research in the field and long-lasting experience employing ICT-based innovations in education is proposing the development of a roadmap for the AI-Enhanced Classroom for Deeper Learning in STEM that facilitates the transformation of the traditional classroom to an environment that promotes the scientific exploration and monitors and supports the development of key skills for all students. The project starts with a foresight research exercise to increase the understanding of the potential, opportunities, barriers, accessibility issues and risks of using emerging technologies (AI-enabled assessment systems combined with AR/VR interfaces) for STEM teaching, considering at the same time a framework for the sustainable digitization of education. The project designs an Exploratory Learning Environment (Discovery Space) to facilitate students’ inquiry and problem-solving while they are working with virtual and remote labs. This enables AI-driven lifelong learning companions to provide support and guidance and with VR/AR interfaces to enhance the learning experience, to facilitate collaboration and problem solving. It also provides Good Practices of Scenarios and pilots to equip teachers and learners with the skills necessary for the use of technology appropriately (the Erasmus+ project’s lifetime: 2023-2015).
- Discrete OptimizationHide
-
Discrete Optimization
Dominik Kamp, Sascha Kurz, Jörg Rambau, Ronan Richter
Optimization is one of most influential digital methods of the past 70 years. In the most general setting, optimization seeks to find a best option out of a set of feasible options. Very often, options consist of a complex combination of atomic decisions. If some of these decisions are, e.g., yes/no-decisions or decisions on integral quantities like cardinalities, then the optimization problem is discrete (as opposed to continuous). For example, your favorite navigation system solves discrete optimization problems whenever you ask for a route, since you can only go this way or that way and not half this way and half that way at the same time. This poster presents, among a brief introduction into the mathematical field, some acadamic and real-world examples for discrete optimization. The main goal is to show how far one can get with this tool today and what has been done by members of the Chair of Economathematics (Wirtschaftsmathematik) at the University of Bayreuth.
- Discrete structures, algorithms, and applicationsHide
-
Discrete structures, algorithms, and applications
Sascha Kurz
The development of digital computers, operating in "discrete" steps and storing data in "discrete" bits, has accelerated research in Discrete Mathematics. Here mathematical structures that can be considered to be "discrete", like the usual integers, rather than "continuous", like the real numbers, are studied. There exists a broad variety of discrete structures like e.g. linear codes, graphs, polyominoes, integral point sets, or voting systems.
Optimizing over discrete structures can have several characteristics. In some cases an optimum can be determined analytically or we can derive some properties of the optimal discrete structures. In other cases we can design algorithms that determine optimal solutions in reasonable time or we can design algorithms that locate good solutions including a worst case guarantee.
The corresponding poster exemplarily highlights results for a variety of different discrete structures and invitesm researchers for discussions about discrete structures and related optimization problems occuring in their projects.
- DiSTARS: Students as Digital Storytellers: STEAM approach to Space ExplorationHide
-
DiSTARS: Students as Digital Storytellers: STEAM approach to Space Exploration
Franz X. Bogner, Catherine Conradty
STEAM education is about engaging students in a multi- and interdisciplinary learning context that values the artistic activities, while breaking down barriers that have traditionally existed between different classes and subjects. This trend reflects a shift in how school disciplines are being viewed. It is driven by a commitment to fostering everyday creativity in students, such that they engage in purposive, imaginative activity generating outcomes that are original and valuable for them. While this movement is being discussed almost explicitly in an education context, its roots are embedded across nearly every industry. A renewed interplay between art, science and technology exists. In many ways, technology is the connective tissue.
DiSTARS tests a synchronized integration of simulating ways in which subjects naturally connect in the real world. Combining scientific inquiry with artistic expression (e.g. visual and performing arts), storytelling, and by using existing digital tools (such as the STORIES storytelling platform) along with AR and VR technology, the project aims to capture the imagination of young students and provide them with one of their early opportunities for digital creative expression. The selected thematic area of study is Space Exploration which despite of the strong gendering of interest in science as the issue of a potential life outside of Earth is interesting for both girls and boys. Students involved in the project work collaboratively in groups to express their visions for the future of space exploration. Each group of students creates a digital story in the form of an e-book (in a 2D or 3D environment) showing how they imagine Mars (or the Moon), the trip, the arrival, the buildings on the planet, the life of humans there. The project focuses at the age range of 10 to 12 years old students (The Erasmus+ project’s lifetime: 2020-2023).
- Distributional Reinforcement LearningHide
-
Distributional Reinforcement Learning
Luchen Li, Aldo Faisal
Distributional Reinforcement Learning maintains the entire probability distribution of the reward-to-go, i.e. the return, providing more learning signals that account for the intrinsic uncertainty associated with policy performance, which may be beneficial for trading off exploration and exploitation and policy learning in general. We first prove that the distributional Bellman operator for state-return distributions is also a contraction in Wasserstein metrics, extending previous work on state-action returns. This enables us to translate successful conventional RL algorithms that are based on state values into distributional RL. We formulate the distributional Bellman operation as an inference-based auto-encoding process that minimises Wasserstein metrics between target/model return distributions. The proposed algorithm, Bayesian Distributional Policy Gradients (BDPG), uses adversarial training in joint-contrastive learning to estimate a variational posterior over a latent variable. Moreover, we can now interpret the return prediction uncertainty as an information gain, from which a new curiosity measure can be obtained to boost exploration efficiency. We demonstrate in a suite of Atari 2600 games and MuJoCo tasks, including well recognised hard-exploration challenges, how BDPG learns generally faster and with higher asymptotic performance than reference distributional RL algorithms.
- ECO2 -SCHOOLS as New European Bauhaus (NEB) LabsHide
-
ECO2 -SCHOOLS as New European Bauhaus (NEB) Labs
Franz X. Bogner, Tessa-Marie Baierl
The Erasmus+ project acronymed NEB-LAB combines the expertise of architects, school principal, community leaders, educators and psychometric experts. It develops within the project’s lifetime (2023-2025) physical pilot sites of schools, universities, and science centers in five European countries (Sweden, France, Greece, Portugal, Ireland) to eco-renovate educational buildings that serve as living labs to promote sustainable citizenship. Within the project frame, the University of Bayreuth assures the assessment work package by measuring the effects on school environments and framing students’ sustainable citizenship. Building on the concept of Open Schooling, the selected pilot sites will develop concrete and replicable climate action plans to be transformed to innovation hubs in their communities, raising citizen awareness activities to facilitate social innovation, promote education and training for sustainability, conducive to competences and positive behaviour for a resource efficient and environmentally respectful energy use. The process is guided and supported by an innovative partnership scheme that brings together unique expertise (including architects and landscape designers, technology and solutions providers, financial bodies and local stakeholders). The project demonstrates that such educational buildings can act as drivers for the development of green neighbourhood “living labs” and guide toward sustainable citizenship. The common feature in all pilot sites will be a by-product of the desire to create a building that inspires forward-looking, inquiry-based learning, and a sense of ownership among students and building stakeholders alike.
- Engineering specific binding pockets for modular peptide binders to generate an alternative for reagent antibodiesHide
-
Engineering specific binding pockets for modular peptide binders to generate an alternative for reagent antibodies
Josef Kynast, Merve Ayyildiz, Jakob Noske, Birte Höcker
Current biomedical research and diagnostics critically depend on detection agents for specific recognition and quantification of protein molecules. Due to shortcomings of state-of-the-art commercial reagent antibodies such as low specificity or cost-efficiency, we work on an alternative recognition system based on a regularized armadillo repeat protein. The project is a collaboration with the groups of Anna Hine (Aston, UK) and Andreas Plückthun (Zürich, CH). We focus on the detection and analysis of interaction patterns to design new binder proteins. Additionally, we try to predict the binding specificity or simulate binding dynamics of those designed protein binders. Here we present our computational approach.
- Explainable Intelligent Systems (EIS)Hide
-

Explainable Intelligent Systems (EIS)
Lena Kästner, Timo Speith, Kevin Baum, Georg Borges, Holger Hermanns, Markus Langer, Eva Schmidt, Ulla Wessels
Artificially intelligent systems are increasingly used to augment or take over tasks previously performed by humans. These include high-stakes tasks such as suggesting which patient to grant a life-saving medical treatment or navigating autonomous cars through dense traffic---a trend raising profound technical, moral, and legal challenges for society.
Against this background, it is imperative that intelligent systems meet central desiderata placed on them by society. They need to be perceivably trustworthy, support competent and responsible decisions, allow for autonomous human agency and for adequate accountability attribution, conform with legal rights, and preserve fundamental moral rights. Our project substantiates the widely accepted claim that meeting these desiderata presupposes human stakeholders to be able to understand intelligent systems’ behavior and that to achieve this, explainability is crucial.
We combine expertise from informatics, law, philosophy, and psychology in a highly interdisciplinary and innovative research agenda to develop a novel ‘explainability-in-context’ (XiC) framework for intelligent systems. The XiC framework provides concrete suggestions regarding the kinds of explanations needed in different contexts and for different stakeholders to meet specific societal desiderata. It will be geared towards guiding future research and policy-making with respect to intelligent systems as well as their embedding in our society. - Fair player pairings at chess tournamentsHide
-

Fair player pairings at chess tournaments
Agnes Cseh, Pascal Führlich, Pascal Lenzner
The Swiss-system tournament format is widely used in competitive games like most e-sports, badminton, and chess. In each round of a Swiss-system tournament, players of similar score are paired against each other. We investigate fairness in this pairing system from two viewpoints.
1) The International Chess Federation (FIDE) imposes a voluminous and complex set of player pairing criteria in Swiss-system chess tournaments and endorses computer programs that are able to calculate the prescribed pairings. The purpose of these formalities is to ensure that players are paired fairly during the tournament and that the final ranking corresponds to the players' true strength order. We contest the official FIDE player pairing routine by presenting alternative pairing rules. These can be enforced by computing maximum weight matchings in a carefully designed graph. We demonstrate by extensive experiments that a tournament format using our mechanism (1) yields fairer pairings in the rounds of the tournament and (2) produces a final ranking that reflects the players' true strengths better than the state-of-the-art FIDE pairing system.
2) An intentional early loss at a Swiss-system tournament might lead to weaker opponents in later rounds and thus to a better final tournament result---a phenomenon known as the Swiss Gambit. We simulate realistic tournaments by employing the official FIDE pairing system for computing the player pairings in each round. We show that even though gambits are widely possible in Swiss-system chess tournaments, profiting from them requires a high degree of predictability of match results. Moreover, even if a Swiss Gambit succeeds, the obtained improvement in the final ranking is limited. Our experiments prove that counting on a Swiss Gambit is indeed a lot more of a risky gambit than a reliable strategy to improve the final rank. - Flexible automated production of oxide short fiber compositesHide
-
Flexible automated production of oxide short fiber composites
Lukas Wagner, Georg Puchas, Dominik Henrich, Stefan Schaffner
In order to enable intuitive on-line robot programming for fiber spray processes, a robot programming system is required which is characterized by its flexibility in programming for the use in small and medium-sized companies. This can be achieved by using editable playback robot programming. In this research project, the editable playback robot programming is applied to a continuous process for the first time in order to enable the robot-supported production of small batches. Thus, a domain expert should be able to operate the robot system without prior programming knowledge, so that he can quickly program a robot path and the associated control of peripheral devices required for a given task. Fundamental extensions are also to be used to investigate possibilities for optimizing robot programs and their applicability within the editable playback robot programming. The fiber spraying process of oxide fiber composites serves as a practical application example, as this material places particularly high demands on the impregnation of fiber bundles and their preservation, for which the fiber spraying process and its automation are particularly suitable. The planned intuitive programming is to be tested as an example on this little-researched composite material, which has great potential for the high temperature application (combustion technology, metallurgy, heat treatment). If successful, the interdisciplinary cooperation between applied computer science and materials engineering provides the framework for the process engineering and materials research of a new class of materials for high-temperature lightweight construction.
- Flow-Design Models for Supply ChainsHide
-

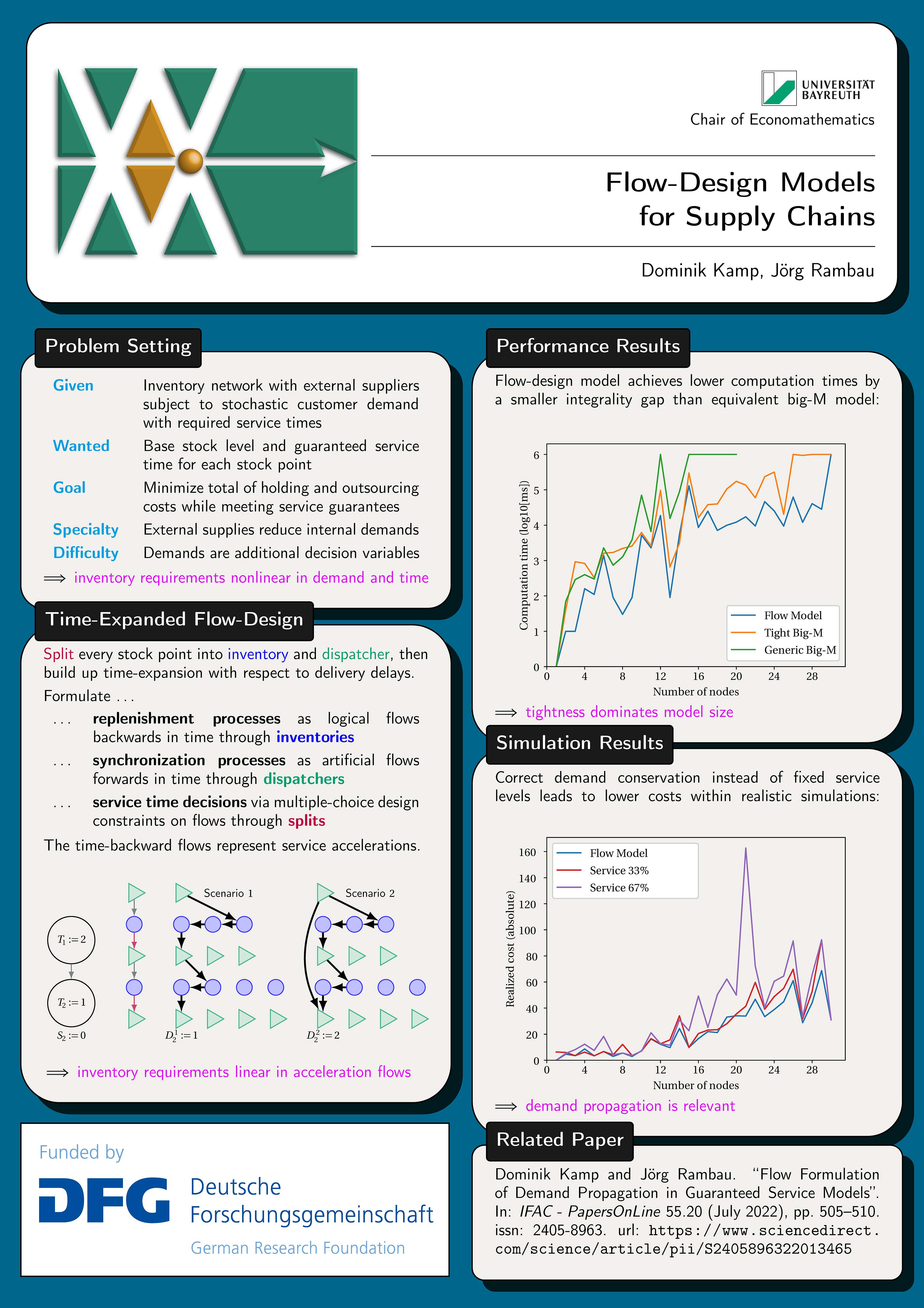
Flow-Design Models for Supply Chains
Dominik Kamp, Jörg Rambau
A main task in supply chain management is to find an efficient placement of safety stocks between the production stages so that end customer demands can be satisfied in time. This becomes particularly complicated in the presence of multiple supply options, since the selection of suppliers influences the internal demands and therefore the stock level requirements to enable a smooth supply process. The so-called Stochastic Guaranteed Service Model with Demand Propagation determines suitable service times and base stocks along a divergent supply chain with additional nearby suppliers, which are able to serve demanded products in stock-out situations. This model is non-linear by design but can be stated as a big-M-linearized mixed integer program. However, the application of established solvers to the original formulation is intractable already for small supply chains. With a novel equivalent formulation based on time-expanded network flows, a significantly better performance can be achieved. Using this approach, even large supply chains are solved to optimality in less time although much more variables and constraints are involved. This makes it possible for the first time to thoroughly investigate optimal configurations of real-world supply chains within a dynamic simulation environment.
- Fluent human-robot teaming for assembly tasksHide
-

Fluent human-robot teaming for assembly tasks
Nico Höllerich
The utilisation of robots has the potential to lower costs or increase production capacities for assembly tasks. However, full automatisation is often not feasible as the robot lacks dexterity. In contrast, purely manual assembly is expensive and tedious. Human-robot teaming promises to combine the advantages of both. Since humans often attribute intelligence to robots, they expect that a robot teaming partner adapts to their preferences. Existing human-robot workspaces, however, do not offer adaption but follow a fixed schedule. Future solutions should overcome this shortcoming. Human and robot should fluently work together and adapt to the preferences of each other. This is possible as humans follow specific patterns (e.g. work from left-to-right, or compose layer-by-layer). Traditional machine learning approaches, such as neural networks, have the required expressiveness to capture and learn those patterns. But they often require large amounts of training data. Our approach avoids this problem by transforming sequences of task steps into a carefully designed feature space. We designed a small neural network specifically for this feature space. Input is a sequence of previous steps and candidates for the next step. Output is a probability distribution over the candidates. That way, the neural network can predict the human’s next step. The result guides the robot decision-making king. The advantage compared to deep learning frameworks is that the network can be trained on the fly while the human is performing the task with the robot. The sequence of previous steps serves as training data for the network. We conducted a user study where human and robot repeatedly compose and decompose a small structure of building blocks. The study shows that our approach leads to overall fluent cooperation. If the robot picks the same step as predicted for the human, fluency drastically decreases – indicating the quality of the prediction.
- Graph Pattern Matching in GQL and SQL/PGQHide
-
Graph Pattern Matching in GQL and SQL/PGQ
Alin Deutsch, Nadime Francis, Alastair Green, Keith Hare, Bei Li, Leonid Libkin, Tobias Lindaaker, Victor Marsault, Wim Martens, Jan Michels, Filip Murlak, Stefan Plantikow, Petra Selmer, Oskar van Rest, Hannes Voigt, Domagoj Vrgoc, Mingxi Wu, Fred Zemke
As graph databases become widespread, JTC1 -- the committee in joint charge of information technology standards for the International Organization for Standardization (ISO), and International Electrotechnical Commission (IEC) -- has approved a project to create GQL, a standard property graph query language. This complements a project to extend SQL with a new part, SQL/PGQ, which specifies how to define graph views over an SQL tabular schema, and to run read-only queries against them.
Both projects have been assigned to the ISO/IEC JTC1 SC32 working group for Database Languages, WG3, which continues to maintain and enhance SQL as a whole. This common responsibility helps enforce a policy that the identical core of both PGQ and GQL is a graph pattern matching sub-language, here termed GPML.
The WG3 design process is also analyzed by an academic working group, part of the Linked Data Benchmark Council (LDBC), whose task is to produce a formal semantics of these graph data languages, which complements their standard specifications.
This paper, written by members of WG3 and LDBC, presents the key elements of the GPML of SQL/PGQ and GQL in advance of the publication of these new standards. - Heterogeneous cell structures in AFM and shear flow simulationsHide
-
Heterogeneous cell structures in AFM and shear flow simulations
Sebastian Wohlrab, Sebastian Müller, Stephan Gekle
In biophysical cell mechanics simulations, the complex inner structure of cells is often simplified as homogeneous material. However, this approach neglects individual properties of the cell’s components, e.g., the significantly stiffer nucleus.
By introducing a stiff inhomogeneity inside our hyperelastic cell, we investigate it during AFM compression and inside shear flow in finite- element and Lattice Boltzmann calculations.
We show that a heterogenous cell exhibits almost identical deformation behavior under load and in flow as compared to a homogeneous cell with equal averaged stiffness, supporting the validity of the homogeneity assumed in both mechanical characterization as well as numerical computations. - High-performance computing for climate applicationsHide
-
High-performance computing for climate applications
Vadym Aizinger, Sara Faghih-Naini
Numerical simulation of climate and its compartments is a key tool for predicting the climate change and quantifying the global and regional impact of various aspects of this change on ecological, economical and social conditions. Dramatically improving the predictive skill of modern climate models requires more sophisticated representations of physical, chemical and biological processes, better numerical methods and substantial breakthroughs in computational efficiency of model codes. Our work covers some of the most promising numerical and computational techniques that hold promise of significantly improving the computational performance of future ocean and climate models.
- How does ChatGPT change our way ouf teaching, learning and examining?Hide
-

How does ChatGPT change our way ouf teaching, learning and examining?
Paul Dölle
ChatGPT can become a tool for our daily work. The tool does not think for us, we can think with the tool. In order for us to be able to do that, we have to understand it, get to know the possibilities and risks and adjust ourselves and the students didactically to it.
The project at ZHL (Center for Teaching and Learning) deals with the effects of automated writing aids on teaching and offers further training opportunities for teachers. - Human-AI Interaction in Writing ToolsHide
-

Human-AI Interaction in Writing Tools
Daniel Buschek, Hai Dang, Florian Lehmann
We explore new user interfaces and interaction concepts for writing with AI support, with recent projects such as: 1) The impact of phrase suggestions from a neural language model on user behaviour in email writing for native and non-native English speakers. 2) A comparison of suggestions lists and continuous text generation and its impact on text length, wording, and perceived authorship. 3) A new text editor that provides continuously updated paragraph-wise summaries as margin annotations, using automatic text summarization, to empower users in their self-reflection. More broadly, our work examines opportunities and challenges of designing interactive AI tools with Natural Language Processing capabilities.
- Impact of XAI dose suggestions on the prescriptions of ICU doctorsHide
-
Impact of XAI dose suggestions on the prescriptions of ICU doctors
Myura Nagendran, Anthony Gordon, Aldo Faisal
Background.
Our AI Clinician reinforcement learning agent has entered prospective evaluation. Here we try to understand (i) how much an AI can influence an ICU doctor’s prescribing decision, (ii) how much knowing the distribution of peer actions influences the doctor and (iii) whether or how much an AI explanation influences the doctor’s decision.Methods.
We conducted an experimental human-AI interaction study with 86 ICU doctors using a modified between-subjects design. Doctors were presented for each of 16 trials with a patient case, potential additional information depending on the experiment arm, and then prompted to prescribe continuous values for IV fluid and vasopressor. We used a multi-factorial experimental design with 4 arms. The 4 arms were baseline with no AI or peer human information; peer human clinician scenario showing the probability density function of IV fluid and vasopressor doses prescribed by other doctors; AI scenario; explainable AI (XAI) scenario (feature importance).Results.
Our primary measure was the difference in prescribed dose to the same patient across the 4 different arms. For the same patients, providing clinicians with peer information (B2) did not lead to an overall significant prescription difference compared to baseline (B1). In contrast, providing AI/XAI (B3-4) information led to significant prescription differences compared to baseline for IV fluid. Importantly, the XAI condition (B4) did not lead to a larger shift towards the AI’s recommendation than the AI condition (B3).Discussion.
This study suggests that ICU clinicians are influenceable by dose recommendations. Knowing what peers had done had no significant overall impact on clinical decisions while knowing that the recommendation came from AI did make a measurable impact. However, whether the recommendation came in a “naked” form or garnished with an explanation (here simple feature importance) did not make a substantial difference. - Invasive Mechanical VentilationHide
-
Invasive Mechanical Ventilation
Yuxuan Liu, Aldo Faisal, Padmanabhan Ramnarayan
Invasive mechanical ventilation, a vital supportive therapy for critically ill patients with respiratory failure, is one of the most widely used interventions in admissions to the PICU: more than 60% of the 20,000 children admitted to UK PICUs each year receive breathing support through an invasive ventilator, spanning for 45.3% of the total bed days. Weaning refers to the gradual process of transition from full ventilatory support to spontaneous breathing, including, in most patients, the removal of the endotracheal tube. The dynamic nature of respiratory status means that what might be 'right' at one time point may not be 'right' at another time point. Acknowledging that this dynamic nature results in wide clinical variation in practice, and that it may be possible to augment clinicians' decision-making with computerised decision support, there has been a growing interest in the use of artificial intelligence (AI) in intensive care settings, both for adults and children. However, the current AI landscape is increasingly acknowledged as incomplete, with frequent concerns regarding AI reproducibility and generalisability. More importantly, there are currently no specific AI systems taking special consideration of features that are distinctive to the paediatric population and could effectively optimizing ventilator management in PICUs.
This work aims to develop an AI-based decision support tool that uses available historical
data for patients admitted to three UK paediatric intensive care units (PICUs) to suggest
treatment steps aimed at minimising the duration of ventilation support while maximizing
extubation successful rates. - Isolating motor learning mechanisms through a billiard task in Embodied Virtual RealityHide
-
Isolating motor learning mechanisms through a billiard task in Embodied Virtual Reality
Federico Nardi, Shlomi Haar, Aldo Faisal
Motor learning is driven by error and reward feedback which are considered to be processed by two different mechanisms: error-based and reward-based learning. While those are often isolated in lab based tasks, it is not trivial to dissociate between them in the real-world. In previous works we established the game of pool billiards as a real-world paradigm to study motor learning, tracking the balls on the table to measure task performance, using motion tracking to capture full-body movement and electroencephalography (EEG) to capture brain activity. We demonstrated that during real-world learning in the pool task different individuals use varying contributions of error-based and reward-based learning mechanisms. We then incorporated it in an embodied Virtual Reality (eVR) environment to enable perturbations and visual manipulations.
In the eVR setup, the participant is physically playing pool while visual feedback is provided by the VR headset. Here, we used the eVR pool task to introduce visuomotor rotations and selectively provide error or reward feedback, as was previously done in lab tasks, to study the effects of the forced use of a single learning mechanism on the learning and the brain activity. Each of the 40 participants attended the lab for two sessions to learn one rotation (clockwise or counter-clockwise) with error feedback and the other with reward, with a coherent different visual feedback provided.
Our behavioural results showed a difference between the learning curves with the different feedback, but with both the participants learned to correct for the rotation, while using separate and single learning mechanisms. - JSXGraph - Mathematical visualization in the web browserHide
-
JSXGraph - Mathematical visualization in the web browser
Carsten Miller, Volker Ulm, Alfred Wassermann
A selection of JSXGraph features are: plotting of function graphs and curves, Riemann sums, support of various spline types and Bezier curves, the mathematical subroutines comprise differential equation solvers nonlinear optimization, advanced root finding, symbolic simplification of mathematical expressions, interval arithmetics, projective transformations, path clipping as well as some statistical methods. Further, (dynamic) mathematical typesetting via MathJax or KaTeX and video embedding is supported. Up to now, the focus was on 2D graphics, 3D support has been started recently.
A key feature of JSXGraph is its seamless integration into web pages. Therefore it became an integral part of several e-assessment platforms, e.g. the moodle-based system STACK, which is very popular for e-assessment in "Mathematics for engineering" courses worldwide. The JSXGraph filter for the elearning system Moodle is meanwhile available in the huge Moodle installation "mebis" for all Bavarian schools, as well as in elearning platforms of many German universities, e.g. University of Bayreuth, RWTH Aachen. The JSXGraph development team has been / is part of several EU Erasmus+ projects (COMPASS, ITEMS, Expert, IDIAM).
- LBM Simulations of Raindrop Impacts demonstrate Microplastic Transport from the Ocean into the AtmosphereHide
-
LBM Simulations of Raindrop Impacts demonstrate Microplastic Transport from the Ocean into the Atmosphere
Moritz Lehmann, Fabian Häusl, Stephan Gekle
We show that raindrop impacts constitute a mechanism for microplastic transport from the ocean into the atmosphere, possibly explaining elevated levels of microplastics detected in the air near the coastline. With the Volume-of-Fluid lattice Boltzmann method, extended by the immersed-boundary method, we perform hundreds of raindrop impact simulations and do statistical analysis on the ejected droplets. Using typical sizes and velocities of real-world raindrops, we simulate straight impacts with various raindrop diameters and oblique impacts, and we find that a 5 mm diameter raindrop impact on average ejects more than 168 droplets and that at least 75 of them are so fast that they reach an altitude above half a meter in the air. We show that the droplets contain microplastic concentrations similar to the ocean a few millimeters below the surface.
- Learning to improvise figured bass - a testbed for cognitive modeling in ACT-RHide
-
Learning to improvise figured bass - a testbed for cognitive modeling in ACT-R
Wolfgang Schoppek
ACT-R is an established cognitive architecture for modeling cognitive and perceptual-motor processes, particularly with respect to learning and memory. It can be regarded as an AI tool based on psychological theory. Different from most contemporary approaches, ACT-R has its focus on symbolic processing.
To explore the potential of this cognitive architecture, I am developing a model of improvising figured bass. This is a musical practice from the baroque period, where players of chord instruments (e.g. cembalo) imrovise a fully harmonized keyboard part from a bass-line with added figures (numbers and symbols).
Improvising figured bass is a complex skill involving a wide range of rules as well as perceptual-motor processes. All that, and even more the additional creative aspect of improvising, brings ACT-R to its limits. I am looking forward to discussing possible solutions from different approaches. - Machine learning the dynamics of liquidsHide
-
Machine learning the dynamics of liquids
Daniel de las Heras, Toni Zimmermann, Florian Sammüller, Sophie Hermann, Matthias Schmidt
Understanding the dynamics of liquids, from microscopic to macroscopic scales, is a significant challenge when starting from the statistical mechanics of an underlying many-body Hamiltonian. In equilibrium, classical density functional theory provides a well-established framework for investigating a wide variety of interfacial and adsorption phenomena, including freezing, and ranging from mesoscopic colloidal to nanoscopic molecular scales. In nonequilibrium the formally exact power functional framework establishes sound relationships of the force fields that drive the motion and their origin in the coupled nature of the many-body problem. Systems of interest range from Lennard-Jones liquids, to monatomic water models and colloidal gel formers. For simple liquids, the functional dependence of the interparticle force field on the motion of the system (kinematic map) can reliably captured via machine learning.
- Migrant Knowledge and Regional Economic DevelopmentHide
-
Migrant Knowledge and Regional Economic Development
Sebastian Till Braun, Richard Franke, Sarah Stricker
This project uses a novel county-level database on German World War II (WWII) refugees to analyze the effects of skilled migration on regional development in West Germany after 1945. After WWII, about eight million displaced persons arrived in West Germany, mainly from the ceded eastern territories of the German Empire. The nature of their displacement caused an unequal distribution of refugees within West Germany. For instance, counties closer to regions of origin experienced a greater influx of refugees after WWII. We use over 2.2 million records of the Equalization of Burden Law—applications in the form of paper files—archived in the Lastenausgleichsarchiv in Bayreuth to estimate county-to-county flows of refugees. We also digitized historical census and GDP data at the county level to identify i) the skill distribution in origin and destination counties, ii) the effect of the refugee inflow on the skill distribution in destination counties, and iii) the impact on regional economic development after WWII. In addition, we use a database of over 18 million geo-referenced patent holders to study the effects of the refugee inflow on innovation. In particular, we test the hypothesis that the high-skilled immigration of two million expellees from the neighboring, highly industrialized Sudetenland facilitated Bavaria’s transformation from a relatively poor, predominantly agricultural state to a high-tech business location after 1945. Preliminary results indicate that the inflow of high-skilled refugees positively affected regional income and innovation. In future work, we plan to use more complete information from the 2.2 million records of the Equalization of Burden Law, including the name of the applicants, their ages, and their lost possessions. To do so, we need to extract handwritten information from the scanned forms automatically.
- Modelling and simulation of refractories’ material properties based on 3D microstructural analysisHide
-
Modelling and simulation of refractories’ material properties based on 3D microstructural analysis
Simon Pirkelmann, Holger Friedrich, Gerhard Seifert, Friedrich Raether
The common goal to achieve climate neutrality implies that thermal processes have to be quickly optimized with respect to energy and material efficiency. Refractories can contribute doubly to these goals, by improved functionality and increased service life in the process they were designed for as well as by minimizing the energy needed for their production.
In this context, digital methods can help to significantly reduce the time and experimental effort for systematic development of refractory materials towards more sustainability.
We present a simulation-based approach to evaluate the influence of material composition on the mechanical strength of refractory materials based on non-destructive analysis of refractory samples. The method aims to identify the most critical structural elements with regard to component failure under thermal or mechanical load, which have to be avoided to improve the reliability of new refractory materials.
In this approach, a neural network is trained and then used for digital image segmentation of 3D computed tomography images of refractory samples. The network is able to distinguish different components of the material such as pores, coarse-grained inclusions and fine-grained matrix. This information is used to generate a voxel-based volumetric model, from which structural properties such as phase fractions, degree of porosity, grain sizes as well as their local spatial distribution can be extracted. By converting representative volume elements into a mesh geometry, finite element analyses of the influence of different thermal and mechanical load cases on the material are done.
By performing these simulations for different material types and a variety of specimens, it becomes possible to evaluate the relationship between the identified structural properties of a specimen and assess the resulting probability of failure. - Modeling Viscosity of Volcanic Melts With Artificial Neural NetworksHide
-
Modelling Viscosity of Volcanic Melts With Artificial Neural Networks
Dominic Langhammer, Danilo Di Genova, Gerd Steinle-Neumann
Since explosive volcanic eruptions are potentially extremely dangerous, volcanic hazard mitigation plans are of the utmost importance. An important part of these plans are numeric simulations of eruptions. Within these, magma viscosity is a key parameter that controls the style of a volcanic eruption, i.e. whether it will be effusive or explosive. Therefore, detailed knowledge of this property is required. Melt viscosity can vary by up to 15 orders of magnitude with temperature and composition. Unfortunately, it is not possible to perform measurements over this range continuously in the laboratory, but only in two distinct temperature regimes, termed high and low viscosity ranges. Since most magmas are erupted at temperatures between these intervals, models are required to extrapolate values at relevant conditions. Current literature models are built using empirical trial-and-error approaches to find equations which fit data with satisfactory quality. This naturally introduces a bias, depending on the equation chosen, which can lead to the neglection of important chemical effects which are present in the data but are not captured in the equation. This frequently leads to inaccurate predictions regarding magmas which are not part of the training data.
In order to make use of as much information contained in the measurements as possible and to obtain a model to predict how composition and temperature control viscosity, we train a feed forward perceptron on a viscosity database of mostly natural silicate melts. This allows us to calculate high- and low-temperature viscosity reliably due to the lack of data within the aforementioned measurement gap. To generate reliable models, the network output, also termed synthetic data, is fit using a physically motivated, temperature dependent equation resulting in a composition specific model. This final approach outperforms current literature equations built upon the empirical approach mentioned before.
- Monitoring and evaluation of additive manufacturing processes using infrared imagery and machine learningHide
-
Monitoring and evaluation of additive manufacturing processes using infrared imagery and machine learning
Niklas Bauriedel, Rodrigo Q. Albuquerque, Julia Utz, Nico Geis, Holger Ruckdäschel
Temperatures have a major impact on the quality and mechanical properties of parts made with fused filament fabrication. Infrared cameras are ideal for monitoring temperatures during the 3D printing process. This work aims to combine machine learning (ML) and infrared imagery to monitor the quality of the 3D printing process and take action if the properties are expected to be poor. For this purpose, ML models were trained to classify the image as reliable (printed parts are visible) or not reliable. The reliable images were further processed using a clustering technique to detect hot/cold spots. Neural networks (NN) were used to predict the mechanical properties (tensile strength) of the entire printed part using all layers. Another NN model was trained to classify individual layers of the same part as unstable, where fracture occurs under load, or stable.
- Motor unit decomposition from surface high-density electromyography as an interfacing modality for human augmentationHide
-
Motor unit decomposition from surface high-density electromyography as an interfacing modality for human augmentation
Renato Mio, Aldo Faisal
High density surface electromyography allows to non-invasively acquire multiple (32 or more) channels of muscle electrical activity data. Because each electrode channel records the summation of several motor neuron potentials, the data acquired from multiple channels can also be decomposed into its sources (individual motor neuron or motor unit activity), a process called motor unit decomposition. Hence, by using blind source separation techniques, the spike trains representing the neurons firing can be decoded. In particular, information from motor unit action potentials such as firing rates, waveforms and conduction velocities can be extracted. Moreover, as a form of neurofeedback training, visualising this decomposed motor unit activity in real time can aid subjects to modulate individual motor neurons firing, something previously considered to be unattainable. This latter approach has potential for using motor unit activity as a neural interfacing method, particularly in cases where an increased neural output or higher number of signals extracted from a single muscle is needed, in contrast to common myoelectric interfaces where just one independent signal is extracted per muscle. In this work, we describe and analyse features resulting from the motor unit decomposition algorithm applied to open-source and experimental upper-limb high density electromyography data. The results are compared with those currently reported in the literature for an initial assessment of the feasibility of applying this method as an interfacing modality to control external devices using individual motor neuron control.
- Multilevel Architectures and Algorithms in Deep LearningHide
-
Multilevel Architectures and Algorithms in Deep Learning
Anton Schiela, Frederik Köhne
The design of deep neural networks (DNNs) and their training are central issues in machine learning. This project, a collaboration with the University of Heidelberg, addresses both of these issues, with the Bayreuth group focusing on training DNNs. The goal is to accelerate the training of DNNs while requiring less human interaction. The latter often originates in the selection of certain hyperparameters, which can significantly influence the behavior of the algorithm. Often, good hyperparameters are determined experimentally, or simple heuristics are used. Our approach is to adapt the hyperparameters to the specific problem during the run of the algorithm automatically, so that the performance of the algorithm does not depend too much on the initialization of the hyperparameters. For this purpose, estimators are developed that approximate certain key quantities, that are necessary for adjusting the hyperparameters. For reasons of efficiency, the estimators must be calculated with minimal computational overhead.
Our current work focuses on theoretical convergence guarantees for such methods. While the stochastic case is more important when it comes to train large machine learning models, such as DNNs, theoretical insights might be derived in the deterministic case first and only later be adapted to the stochastic setting.
- Multiphysics simulation of electromagnetic heating in bead foams for high frequency weldingHide
-
Multiphysics simulation of electromagnetic heating in bead foams for high frequency welding
Marcel Dippold, Holger Ruckdäschel
Multiphysics simulations are a powerful tool for understanding complex interactions between different materials in real production technologies. In this study, electrical impedance spectroscopy is used to determine the dielectric properties of polymer base materials and corresponding bead foams. In combination with other important thermal properties and process parameters, the complex dielectric permittivity provides the temperature-dependent input for the subsequent coupled electrothermal simulation. The software used is COMSOL Multiphysics, resulting in local temperature profiles and power consumption over time of fusing. These results are then validated with data from the real process to optimize the digital twin and further improve the innovative technology.
- National Research Data Infrastructure for and with Computer Science (NFDIxCS)Hide
-
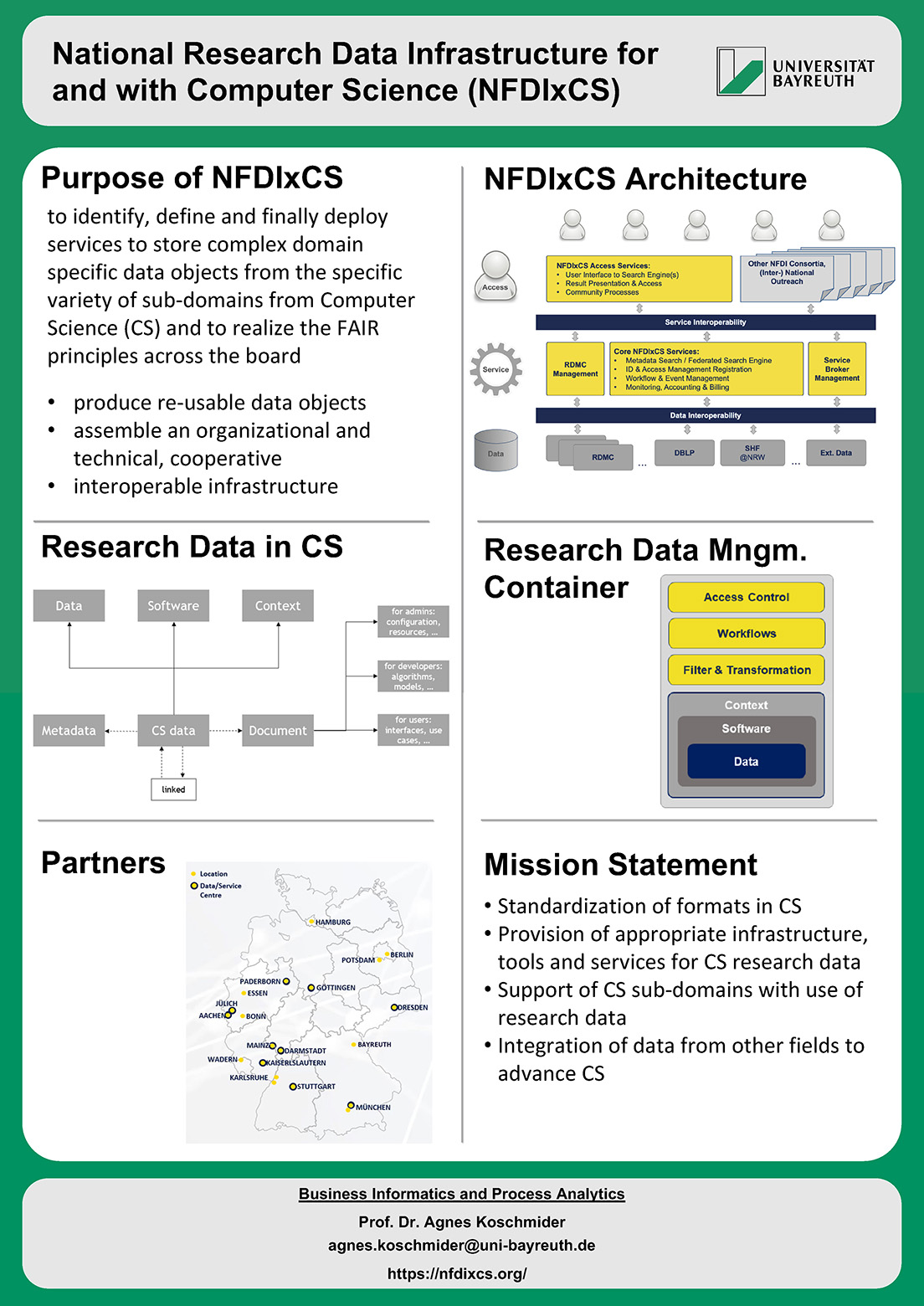
National Research Data Infrastructure for and with Computer Science (NFDIxCS)
Agnes Koschmider
The main goal of the project NFDIxCS is to identify, define and finally deploy services to store complex domain specific data objects from the specific variety of sub-domains from Computer Science (CS) and to realize the FAIR principles across the board. This includes to produce re-usable data objects specific to the various types of CS data, which contain not only this data along with the related metadata, but also the corresponding software, context and execution information in a standardized way. The key principle in NFDIxCS is to assemble an organizational and technical, cooperative and interoperable infrastructure to join the available forces of relevant services and actors from and for CS.
The Process Analytics research group@UBT will design techniques for semantic data management and the association of data with FAIR principles. First, we will evaluate entities, relationships, functions and axioms hold for all sub-disciplines and will define and formalize an upper ontology. The formalized model will be implemented in an ontology language. Next, the ontology will be used as a schema layer for a knowledge graph. Finally, metadata will be used to validate the designed techniques. Metadata will be standardized in terms of an ontology with unique identifiers. - Needed: AI-driven prediction of protein structure and dynamics from biomolecular nuclear magnetic resonance spectroscopyHide
-
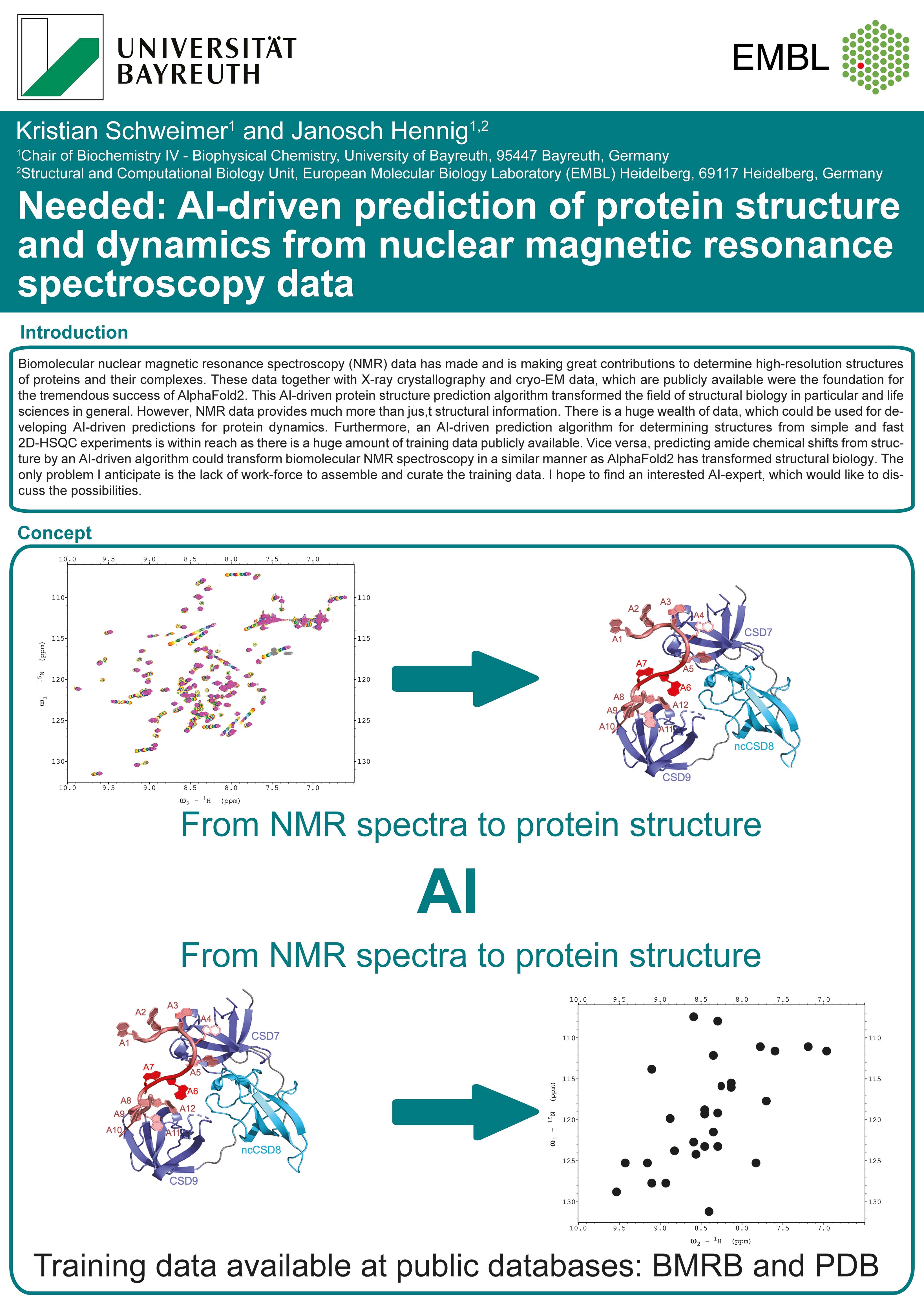
Needed: AI-driven prediction of protein structure and dynamics from biomolecular nuclear magnetic resonance spectroscopy
Janosch Hennig
Biomolecular nuclear magnetic resonance spectroscopy (NMR) data has made and is making great contributions to determine high-resolution structures of proteins and their complexes. These data together with X-ray crystallography and cryo-EM data, which are publicly available were the foundation for the tremendous success of AlphaFold2. This AI-driven protein structure prediction algorithm transformed the field of structural biology in particular and life sciences in general. However, NMR data provides much more than just structural information. There is a huge wealth of data, which could be used for developing AI-driven predictions for protein dynamics. Furthermore, an AI-driven prediction algorithm for determining structures from simple and fast 2D-HSQC experiments is within reach as there is a huge amount of training data publicly available. Vice versa, predicting amide chemical shifts from structure by an AI-driven algorithm could transform biomolecular NMR spectroscopy in a similar manner as AlphaFold2 has transformed structural biology. The only problem I anticipate is the lack of work-force to assemble and curate the training data. I hope to find an interested AI-expert, which would like to discuss the possibilities.
- Network Embedding for Economic IssuesHide
-
Network Embedding for Economic Issues
Simon Blöthner, Mario Larch, Mirco Schönfeld
Every economic transaction can be seen as the interaction between multiple parties, which results in a network when aggregated to the market level. Viewing economic transactions as networks enables us to utilize recent developments in graph neural networks to better understand the underlying economic process. Graph neural networks make use of local information and the structural role that a node plays in the network, which is crucial in understanding transactions, but is not adequately captured by conventional methods used in economics. The high flexibility of this approach enables the modelling of a multitude of economic questions.
Given the distinctive properties inherent to economic data, such as (apparent) infinite mean phenomena, methods developed in a purely theoretical, computer science or statistics framework must be adapted to cope with these requirements. A deeper understanding of the economic processes will help to choose and develop appropriate algorithms for information propagation through network-like structures.
With this work, we propose our research concept on node and graph embedding to account for the complexity of markets and to adapt the methods in such a way that questions from economic research on markets can be answered better than before. The determinants of membership in free trade agreements, network properties of trade flows, and the specifics of European energy markets are to be investigated and explained in unprecedented depth. The influences of contextual factors will be taken into account and a dynamic view will be taken, which has not been possible so far in the analysis of economic networks.
- nMPyC -- A Python Package for Solving Optimal Control ProblemsHide
-

nMPyC -- A Python Package for Solving Optimal Control Problems
Lars Grüne, Lisa Krügel, Jonas Schießl
Optimal control problems aim to optimize an objective function that depends on the state of a dynamical system, which evolves over a certain time horizon. Particularly challenging are optimal control problems on long or infinite time horizons. A popular method to solve such optimal control problems is model predictive control. This method splits the system into subproblems on short time horizons and solves them with efficient numerical methods. Optimal control problems occur in many applications, i.e. in energy systems, autonomous driving, chemical engineering, or in economy.
We present a tool to solve optimal control problems numerically in Python without knowledge of the theoretical background of model predictive control. This tool, a Python package called nMPyC, uses well-known and efficient optimization interfaces such as CasADi or SciPy and aims to provide a simple syntax for formulating the problem in Python. In order to call the optimization method, only the necessary parameters of the optimal control problem, such as the cost function, the system dynamics, or constraints, have to be entered. The complete optimization is performed automatically without needing further adjustments, and the results can be visualized in various ways. Nevertheless, adjusting a wide range of optimization parameters is also possible for an advanced user. We illustrate the nMPyC package with numerical examples and simulations and we also provide the possibility to test nMPyC during the poster session. - Numerical investigations of deep Earth processesHide
-
Numerical investigations of deep Earth processes
Marcel Thielmann, Andrea Piccolo, Arne Spang
The continuously changing surface of the Earth is shaped by tectonic and climatic processes. Distinguishing the relative importance of these processes is elusive, as their coupled nature makes it difficult to quantify their individual contribution to surface deformation. As a first step towards deciphering the impact of internal (tectonic) and external (climatic) on surface deformation, it is necessary to quantify the processes occurring in the deep Earth. These processes occur on multiple scales, ranging from grain-scale interactions in polycrystalline aggregates to large-scale deformation of the entire lithosphere, the Earth's rigid outermost shell. To further complicate matters, the different processes not only occur on different spatial scales, but also on different temporal scales, ranging from thousands of years to seconds. Linking these multiscale processes and their mutual feedbacks has proven to be a challenging task.
Geodynamical numerical modelling has shown to be a very valuable tool to quantify the different processes and to link the different involved scales. Here, we summarize some of the ongoing efforts to better understand the processes resulting in localization of deformation in the deep Earth, which may ultimately result in deep earthquakes. The existence of these earthquakes has been known since about 100 years. However, to this day, the exact processes responsible for these events are not fully understood. Using high resolution 3D lithosphere-scale models as well as small-scale models of rock deformation involving complex rheologies and different nonlinear feedbacks, we aim to determine the processes resulting in deep earthquakes. - Numerical Study of the driving mechanisms behind the slipper motion of red blood cells in rectangular microchannelsHide
-
Numerical Study of the driving mechanisms behind the slipper motion of red blood cells in rectangular microchannels
Berin Becic, Katharina Grässel, Stephan Gekle
Red blood cells in rectangular micro channel flows exhibit two types of motions. At low velocities they tend to migrate towards the centre
of the cross-section and take symmetric croissant like shapes whereas for high velocities they migrate along the axis with the larger dimension
and take an asymmetric slipper shape. Based on these results the behaviour of the asymmetric off-centred slipper-movement was studied further via the boundary integral method. As this method is based on rewriting the Stokes equation into a boundary-integral over the RBC’s surface it is not necessary to discretize the surrounding fluid. Thus it is possible to implement truly infinite boundary conditions for the flow velocity. This approach made it possible to decompose the complex flow profile in the rectangular channel into different components and, crucially, differentiating between the effects stemming from the flow field and the ones stemming from the hydrodynamic interaction of the walls with the RBC. Thus we were able to identify the mechanisms responsible for the formation of the slipper state. In detail we found that the flow profile along the axis of the RBC's motion doesn't suffice to explain its occurrence and instead the corresponding perpendicular flow component plays a crucial role in order to stabilise this state. - Object detection with a Fast Region-based Network for measurement of sublethal effects in ecotoxicological risk assessmentHide
-
Object detection with a Fast Region-based Network for measurement of sublethal effects in ecotoxicological risk assessment
Philipp Kropf, Magdalena Mair, Matthias Schott
Ecotoxicological risk assessments nowadays primarily focuses on lethal effects. Lethal effects are easy to study but omit the harmful consequences sublethal doses of toxins can have on individuals and ecosystems. Evaluation of these risks is a time-consuming and costly endeavour with many measurable endpoints, that have different biological implications. Different species of the genus Daphnia are commonly the first tested species for aquatic toxicity estimations. Daphnids are planktonic invertebrates, that build the foundation of standing water food webs. We develop a machine learning based workflow with a Fast Region-based Convolutional Network (Fast-RCNN) architecture, which automatically detects daphnid body parts and measures the body dimensions. Daphnid body parts are detected reliably in correct position and size with a mean average precision of 48% in a dataset including low quality quality images. We also classify 5 common Daphnia species (D. magna, D. pulex, D. longicephala, D. longispina and D. cucullata) species with 93% accuracy. This framework is planned to be expanded to automatically count of life history parameters and detect daphnia heart rates. We also want to extent the object detection tasks with applications like life-stage detection and inducible defence classification. This will drastically reduce the time needed for most sublethal effect studies and should perform with a comparable accuracy to humans.
- Offline Model-Based Bayesian Distributional Reinforcement Learning with Exact Aleatoric & Epistemic Return UncertaintiesHide
-
Offline Model-Based Bayesian Distributional Reinforcement Learning with Exact Aleatoric & Epistemic Return Uncertainties
Filippo Valdettaro, Aldo Faisal
Reinforcement learning (RL) agents can learn complex sequential decision making and control strategies, often above human expert performance levels. In real-world deployment it becomes essential from a risk, safety-critical, and human interaction perspective for agents to communicate the degree of confidence or uncertainty that agents have with respect to the outcomes and account for it in its decision-making. We assemble here a complete pipeline of modelling uncertainty in the finite, discrete-state setting. First, we use methods from Bayesian RL to capture the posterior uncertainty in environment model parameters given the available data. Next, we employ distributional ideas to determine exact values for the return distribution's standard deviation, taken as the measure of uncertainty, for given samples from the environment posterior (without requiring quantile-based or similar approximations of conventional distributional RL). We then systematically decompose the agents uncertainty into epistemic and aleatoric uncertainties. This allows us to build an RL agent that that quantifies both types of uncertainty and takes into account its epistemic uncertainty belief to inform its optimal policy. We illustrate the capability of our agent in simple, interpretable gridworlds and in a clinical decision support system (AI Clinician) which makes real-time treatment recommendations to treat sepsis in intensive care units.
- On The Nature Of Surgical Movement: Using Machine Learning To Quantify Surgical MotionHide
-
On The Nature Of Surgical Movement: Using Machine Learning To Quantify Surgical Motion
Amr Nimer, Alex Harston, Aldo Faisal
Introduction
The kinematic analysis of the motion of neurosurgeons poses an interesting challenge, as surgical movements are neither ”natural”, being highly specific to brain surgery, nor are they rigid, as a variety of actions in different orders of execution may achieve the same goal. In this study, we compare the statistics of expert neurosurgeons undertaking a simulated brain operation with established kinematic datasets.
Materials and Methods
A full-body motion capture suit utilizing Inertial Measurement was used to capture the motion of expert neurosurgeons whilst performing a procedure on a 3D-printed brain model. The same suit was used in previous projects to capture the kinematics of subjects undertaking omelette cooking, and pool players repetitively hitting a billiard ball. The basic statistics of the three groups, the inter-group divergence metrics, and dimensionality reduction were investigated.Results
The pool motion data needed far less components to account for 70% of the variance. An inflection point occurs at the 74% mark, after which more components are needed to explain variance in surgery than in cooking. The basic statistics showed a similar pattern. The surgical procedure showed significantly more deviation than natural data across all joints in joint angle changes as well as angular velocity.Discussion
It is not surprising that the laboratory based repetitive stereotypical movements of reiterative billiard shots needed fewer components to account for the variance. However, the fact that more components are needed to explain the variability in surgical motion data after the aforementioned inflection point is more challenging to explain. We posit that, although stereotypical identical movements may explain the majority of surgical kinematics, the finer movements that differentiate one surgical subtechnique from another account for this phenomenon.Conclusion
To the best of our knowledge, this is the first true behavioral characterization study of neurosurgical experts. In this study, we show that the statistics of surgical motion differs significantly from both laboratory-based and real-world motion data. This work has considerable scope for future data-driven analyses of expert surgical motion. - Optical 2D spectroscopy of a single moleculeHide
-
Optical 2D spectroscopy of a single molecule
Markus Lippitz
We plan to excite a single dye molecule by a well-controlled sequence of four laser pulses and detect the arrival time of the emitted fluorescence photons on a picosecond time scale. The relative phase of the laser pulses and the exact arrival times allow us to calculate 2D spectra that contain information about interaction of states, not only their energy.
The problem arises when looking at a single molecule which emits only about 1 million photons until it bleaches. We need a method to optimally chose the laser phase parameters, based on the already detected photons, to maximize the information content of the experiment. Sparse sampling or Bayesian optimization would be interesting.
- Optimal Control of Acoustic Levitation DisplaysHide
-
Optimal Control of Acoustic Levitation Displays
Viktorija Paneva, Arthur Fleig, Diego Martinez Plasencia, Timm Faulwasser, Jörg Müller
Acoustic levitation displays use ultrasonic waves to trap millimetre-sized particles in mid-air. Recent technological advancements allowed us to move the levitated particles at very high speeds. This was crucial for developing Persistence of Vision displays using acoustic trapping, that is, displays that present visual content within the integration interval of human eyes of around 0.1s. However, the problem of how to control this dynamical system (i.e., how to apply the acoustic force to obtain the desired particle movement), as to follow a pre-determined path in minimum time was largely unsolved until now. In my research, I develop an automated optimization pipeline that produces physically feasible, time-optimal control inputs that take into account the trap-particle dynamics and allow the rendering of generic volumetric content on acoustic levitation displays, using a path-following approach.
- Optimal Feedback Control with Neural NetworksHide
-

Optimal Feedback Control with Neural Networks
Lars Grüne, Mario Sperl
In this poster session, we study the use of artificial neural networks in the context of optimal control problems. Such problems occur in many applications, e.g., power systems, robotics and autonomous driving. More precisely, we discuss the ability of neural networks to compute a control strategy that minimizes a cost functions with respect to some given dynamics. Common numerical methods for such problems often suffer from the so-called curse of dimesionality. That means their numerical effort grows exponentially with the number of variables. Thus, these approaches are confined to low-dimensional settings. However, it is known that neural networks are capable of overcoming this curse of dimensionality under certain conditions. We identify such conditions in the context of optimal control problems and construct a neural network architecture as well as a training algorithm for efficiently solving the problem. The training process of our neural network is illustrated with a numerical test case.
- Patient Administrative DataHide
-
Patient Administrative Data
Benjamin Post, Roman Klapaukh, Stephen Brett, Aldo Faisal
Emergency hospital admissions are straining health systems internationally and electronic healthcare records (EHRs) offer an attractive option to help manage this crisis. Research using these resources has rapidly proliferated, but a key component of their data has received little attention: patient administrative data. These data are simple, reliable and common to most EHR databases. In this country-wide observational study, we show that purpose-built artificial intelligence (AI) models can capture informative patterns of patient interactions from primary care EHR administrative data. We reveal distinct interaction patterns that are associated with different hospital admission rates. We then train emergency hospital admission predictors using these AI-captured primary care interaction patterns combined with a sparse set of administrative data. Our best-performing prediction model achieves an area under the receiver operating characteristic curve of 0.821, with a precision of 0.935. When compared to a more conventional modelling approach that uses clinical data, we achieve comparable performance, but require 1/10th as many features. In summary, we demonstrate that non-clinical EHR data can be harnessed to capture valuable patterns of primary care interaction and these patterns can be used to train simple but high-performance emergency hospital admission predictors
- Predicting proprioceptive cortical anatomy and neural coding with topographic autoencodersHide
-
Predicting proprioceptive cortical anatomy and neural coding with topographic autoencoders
Max Grogan, Kyle Blum, Yufei Wu, Alex Harston, Lee E Miller, Aldo Faisal
Proprioception is fundamental for the control of movement, its loss producing profound motor deficits. Yet basic questions of how pose and movement are represented, as well as how these representations are arranged across the somatosensory cortex, are unclear. To this end, we adopt a task-driven modelling approach, using a spiking variational autoencoder to approximate a population of cortical neurons. We optimize the model to encode natural movement stimuli derived from recordings of human kinematics and impose biological constraints which we hypothesise to be important for reproducing characteristics of proprioceptive neural coding, namely, enforcing a spike-based code and implementing lateral effects between neighbouring neurons in the model to drive topographical structure in neural tuning. To evaluate the effectiveness of these principles at reproducing empirical observations in neural data (without directly fitting to neural data), we task our model with encoding movement kinematics during a centre-out reaching task and compare activity in modelled neurons to recorded neurons in area 2 of monkeys performing the same task. The model reproduces several key features of neural tuning at both the level of individual neurons, and the spatial organisation of their tuning across the cortical surface. Furthermore, we demonstrate the importance in training on data from the true distribution of natural behaviour, with the model failing to reproduce key properties of the empirical data when trained on stereotyped reaching behaviour only. We then highlight two testable predictions made by the model: 1. The arrangement of directional tuning across the cortex has a blob-and-pinwheel-type geometry. 2. Few neurons encode just a single joint. In summary, the topographic VAE (Blum et al, 2021) provides a principled basis for understanding sensorimotor representations and their spatial organisation in cortex. These basic scientific principles may have application to the restoration of sensory feedback in brain-computer interfaces (Weber et al, 2012).
- Process Analytics Pipeline for Sensor Data, Time Series and Video DataHide
-
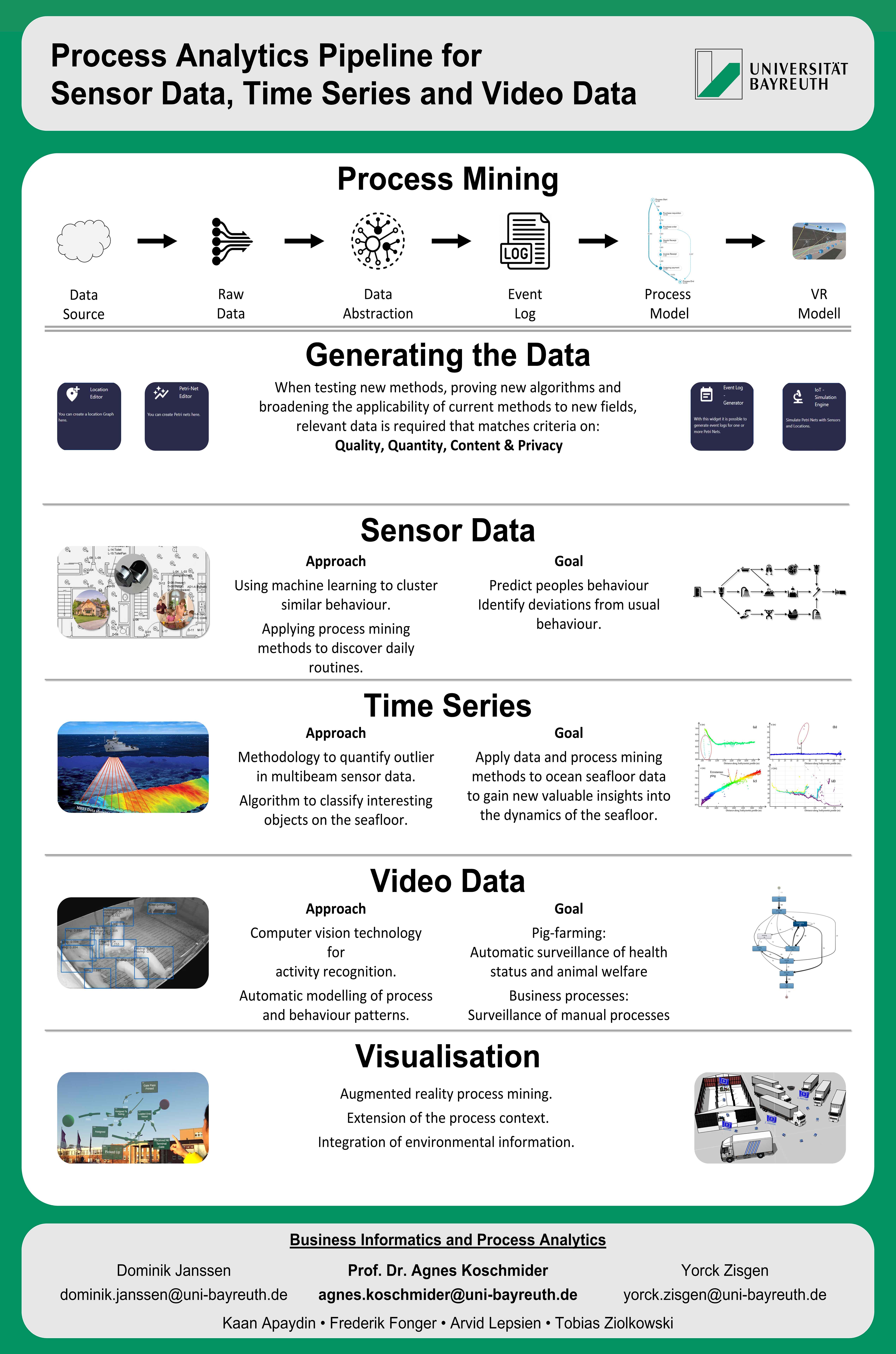
Process Analytics Pipeline for Sensor Data, Time Series and Video Data
Agnes Koschmider, Dominik Janssen, Yorck Zisgen
Disciplines like engineering, life and natural sciences have a high demand for efficient data analytics. Their main purpose is to get new insights into data and in this way to complement traditional techniques like computer simulation.
The Process Analytics research group@UBT develops theoretical concepts for efficient processing and analysis of sensor event data, time series and video data. The techniques are validated using software prototypes. Particularly, the research group designs concepts for the extraction of cause-effect chains in data with the aim of providing new insights into the data through data-driven approaches and AI methods. The data analysis focuses on sensor event data, time series and video-based data, and are intended identifying outliers or making predictions. The application scenarios have a wide focus and range from sensor event data in medical applications and smart home, time series from geography or multibeam data from marine science. Usually there is a matter of data quality in the application domains. To bridge the gap, the research group develops a tool for synthetic data.
To sum up, our research interest broadly explores:
• How to design a framework for the efficient processing of low-level data allowing to extract process knowledge?
• How can machine learning be used to increase data quality (e.g. outlier) and thus accelerate data and process analysis?
• How can synthetic data be efficiently generated that enable privacy-awareness or distributed analysis?
• How can machine learning be used to reduce the involvement of users, but to increase the quality of the data-driven, discovered processes?We are involved in several third-party funded projects and are open to (interdisciplinary) collaboration. The purpose of our poster would be to present our latest research results.
- Processing and analyzing spatially resolved mass spectrometric dataHide
-
Processing and analyzing spatially resolved mass spectrometric data
Andreas Römpp, Matthias Ochs
Mass spectrometry imaging (MS imaging) is an analytical technique that provides spatially-resolved molecular information for a wide range of compound classes and applications. MS images contain mass spectral and spatial information. Open data formats are key to facilitating data sharing, integration and interoperability. The imzML format has drastically improved these aspects of mass spectrometry imaging data. We have developed a number of tools based on the imzML format that range from basic pre-processing to interpretation and visualization of biological processes. Applications range from the analysis of processed food to evaluation of the effect of microplastics.
- Regional Industrialisation in (Southwest) Germany: Patterns, Diffusion and Long-Term EffectsHide
-
Regional Industrialisation in (Southwest) Germany: Patterns, Diffusion and Long-Term Effects
Sebastian Braun, Richard Franke, Timur Öztürk
Germany's rapid industrialization in the 19th century marked a major shift in its economic development. This period saw the adoption of new technologies and forms of production, the emergence of new industries, and a decline in mortality and fertility rates. However, these transformation processes varied greatly across regions. Our research project aims to examine: (1) the diffusion of steam technology at the plant level, and (2) the geography of the demographic transition at the parish level. The project will compile two novel datasets that will significantly enrich the sources available for quantitative studies on regional industrialisation in Germany.
Research project 1 will shed new light on barriers and pathways to technology adoption for a fascinating historical case: the diffusion of steam technology in Württemberg. Our analysis will be the first to provide a plant-level perspective on the adoption of steam, the key technology during Germany’s industrialization. To do so, the project will construct a novel, plant-level dataset on the adoption of steam engines based on reports published annually by Württemberg’s Ministry of the Interior. The data contain a wealth of information, handwritten in kurrent script, on, e.g., the type and producer of each steam engine, which we collect using Artificial Intelligence.
The drivers of the fertility and mortality decline are still the subject of considerable debate. Research project 2 will provide new evidence on the timing and spread of the demographic transition at the parish level. Based on a newly digitized dataset of annual vital and marriage statistics for the universe of Württemberg’s localities, we will first describe key spatial patterns of the state’s demographic transition in 1850-1939 using GIS methods. We will then exploit the data’s panel structure to study the causal effect of potential drivers of the demographic transition.
- Reliability of AI Applications and Confidence into Results – Example of Authenticity Testing of FoodHide
-

Reliability of AI Applications and Confidence into Results – Example of Authenticity Testing of Food
Stephan Schwarzinger, Felix Rüll, Peter Kolb
Physico-chemical experiments often yield massive data sets, from which multiple information can be extracted by applying concepts of machine learning and AI. When applied to chemical data this is termed chemometrics. In recent times, not only the obvious information on chemical composition (properties) is in the focus of such studies. Increasingly, indirectly related properties are being extracted from such data in an untargeted manner. This involves assignment of samples to classes of properties (e.g., concerning origin, variety, given properties, or simply as authentic or not authentic), for which discriminating variables (substances, chemical properties, spectral signals etc.) are not known a priori. Many parameters exist that describe the predictive performance of such models, but not all that are commonly applied are useful when applied to real life AI-problems, which often involve imbalanced data sets and different weights for false assignments. For instance, work in our group shows that the Matthews Correlation Coefficient is much better suited for this purpose in comparison to the widely applied accuracy. Moreover, there is a lack of approaches describing the reliability of the result for a new sample subjected to an AI-model. We have developed a concept providing an analog to experimental measurement uncertainties for AI-derived results. Using these concepts it is not only possible to provide a reliable description of the overall performance of an AI-model, which is useful for efficient AI-model optimization. It also allows judgment on the validity of the result for each individual new sample subjected to the resulting AI-model, which is critical for application by allowing adjustment of decision criteria to ensure a certain confidence level for the result. Here, we present an application to authenticity analysis of grain variety testing by near infrared spectroscopy.
- Research outline of doctoral thesis (within media studies)Hide
-
Research outline of doctoral thesis (within media studies)
Lisa Weging
As a research assistant at the Chair of Digital and Audio-Visual Media (Prof. Hanke), I am currently (since 01/2022) working on my doctoral thesis, which focuses on the implications of machine-learning-based image synthesis viewed from a media studies perspective.
In December 2022, the image-editing app Lensa suddenly became the center of attention, yet the app is just one example of the developments in this field. The General-Adversarial-Network (short: GAN) framework (Ian Goodfellow, 2014), the Lensa predecessor Prisma (both Prisma Labs, 2016), collaborative art projects like Artbreeder (formerly: Ganbreeder, 2018) all demonstrate the increasing technical capabilities of machine learning in image synthesis. These advances have allowed for the creation of synthetic visualizations that are leaving the sheltering field of research and have the potential to enter the commercial market, thus crossing over into daily life as another commodity of visual culture.
However, it is important to critically analyze the visual material produced by these systems. My research aims to explore the extent to which these synthetic images represent or alter our understanding of the world, to what extent stereotypes are consolidated, discriminatory representations are reproduced, as well as how identities are constructed within them.
In their process of visualizing identities, machine-learning-systems operate with attributes that are determined as discrete and static. This contrasts with schools of thought such as critical theory, as also employed in media studies, in which identity is understood as "malleable and constructed through interaction" (see Judith Butler or Karen Barad) (cf. Lu, Kay, McKee 2022). In this area of conflict, in order to critically approach machine learning generated visual content from an intersectional perspective (regarding issues of gender, race, sexuality, and other markers of identity) one must consider how these representations are technologically produced. Where these conflicts become visible, we can identify and address accountabilities.
Through case studies of various projects in fine and applied arts, I hope to identify and address the structures of discrimination that may be inscribed into the process of machine-learning image synthesis, and explore ways to subvert these structures. Only by examining points of accountability, we can in future create representations of identity that accurately reflect the interactive and malleable nature of identity. - Safety assessment of reinforcement learning in healthcare: fron training to realistic deploymentHide
-
Safety assessment of reinforcement learning in healthcare: from training to realistic deployment
Paul Festor, Myura Nagendran, Aldo Faisal, Matthieu Komorowski
Promising results have been shown on AI-based decision support systems for clinical applications. In particular, reinforcement learning (RL) systems have the potential to learn strategies that surpass human performance on complex decision-making systems. While a lot of research has been done on such models on synthetic or retrospective data, the community still faces a strong barrier to bedside deployment, in part due to concerns for patient safety. In this work, we demonstrate a full safety assessment cycle for a reinforcement-learning based clinical decision support system for sepsis cardiovascular management. After demonstrating how retraining the system with safety constraints has little impact on the estimated performance, we ran a simulation study in physical real life simulation facility in a London hospital and closed the loop to include the human factor in the safety analysis. This work provides an illustration that increasing safety does not necessarily mean sacrificing efficacy, illustrates clinical variability in a controlled setting for the clinical problem at hand as well as estimated of the influence of unsafe decisions on treatment decisions. This work shows the importance of properly preparing clinical teams before deploying a RL-based clinical decision support systems and advice on doing so.
- Sample-complexity of goal-conditioned Hierarchical Reinforcement LearningHide
-
Sample-complexity of goal-conditioned Hierarchical Reinforcement Learning
Arnaud Robert, Ciara Pike-Burke, Aldo A. Faisal
What is the benefit of hierarchical decomposition over monolithic solutions to reinforcement learning? In Hierarchical Reinforcement Learning (HRL), algorithms can perform planning at multiple levels of abstraction. Empirical results have shown that state or temporal abstractions might significantly improve the sample efficiency of algorithms. Yet, we still have an incomplete theoretical understanding of the basis of those efficiency gains. Here, we are able to derive analytical bounds for the proposed class of goal-conditioned RL algorithms (e.g. Dot-2-Dot) that lead us to a novel Q-learning algorithm. Specifically, we derive an analytical lower bound on the sample-complexity of such HRL algorithms -- illustrating clearly when HRL can lead to improved performance. This allows us to propose a simple Q-learning-type algorithm that leverages goal hierarchical decomposition. We empirically validate our findings by using a spectrum of hierarchical tasks that allow us to manipulate task complexity over multiple orders of magnitude. Our findings outline a principled approach to understanding when to use hierarchical goal abstractions in RL and how to leverage them.
- Scattered Data ModellingHide
-
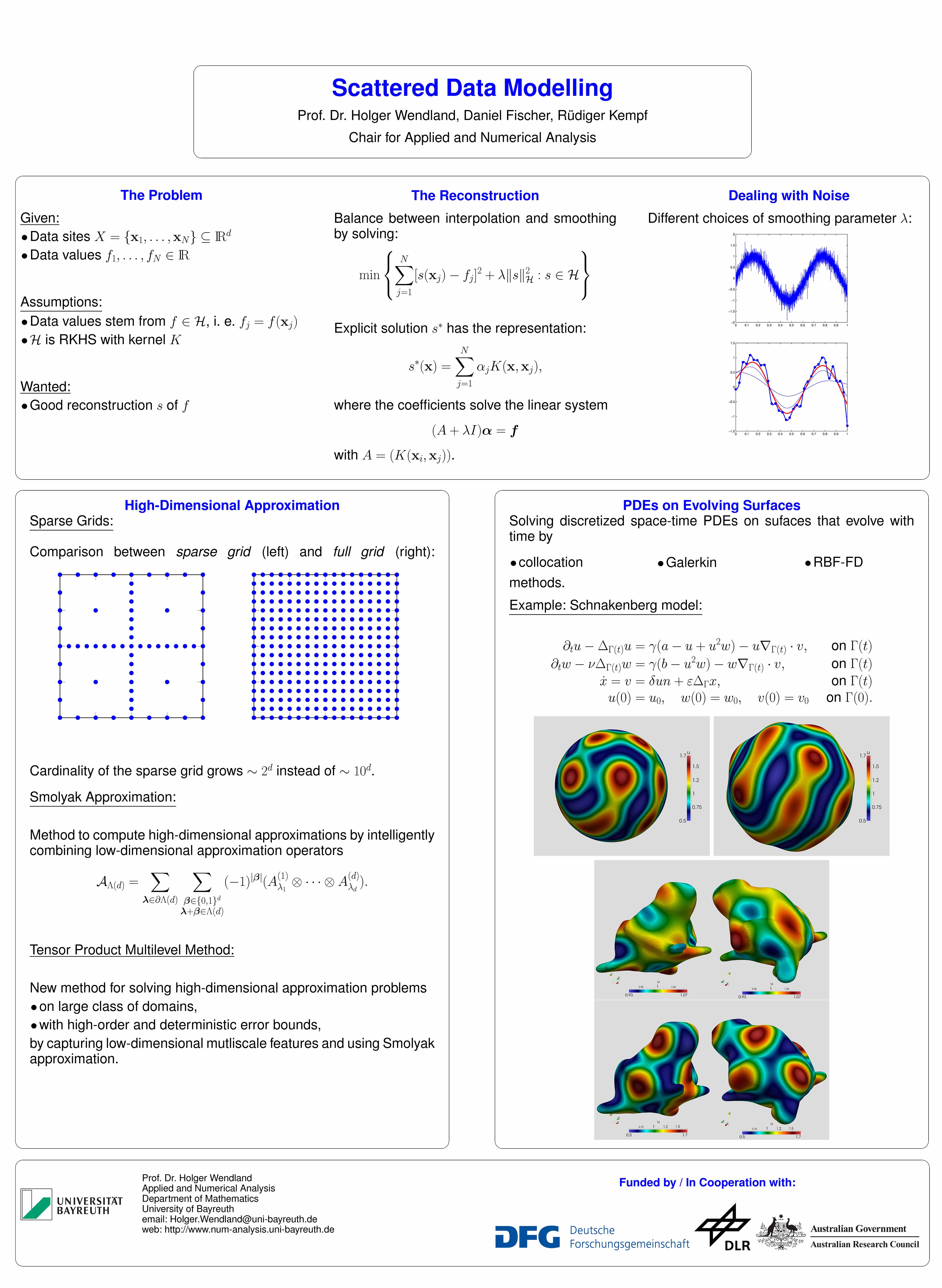
Scattered Data Modelling
Daniel Fischer, Rüdiger Kempf, Holger Wendland
Our research is concerned with topics from applied mathematics, numerical analysis and scientific computing. In particular, we develop, analyse and validate current methods in multivariate and high-dimensional approximation theory. The focus is on meshfree, data-driven, kernel-based methods such as radial basis functions, moving least-squares and particle methods. We are also interested in applications of these methods, for exampe for solving partial differential equations, within learning theory and data analysis.
- Semantic anchors to guide topic models on short text corporaHide
-

Semantic anchors to guide topic models on short text corpora
Florian Steuber, Mirco Schönfeld
Documents on social media are formulated in short and simple style, instead of being written extensively and elaborately. Further, the core message of a post is often encoded into characteristic phrases called hashtags. These hashtags illustrate the semantics of a post or tie it to a specific topic. We propose an approach of using hashtags and their surrounding texts to improve topic modeling of short texts. We use transfer learning by applying a pre-trained word embedding of hashtags to derive preliminary topics. These function as supervising information, or seed topics and are passed to Archetypal LDA (A-LDA).
Archetypal LDA is a topic model tailored to short texts containing "semantic anchors" which convey a certain meaning or implicitly build on discussions beyond their mere presence. A-LDA is an extension to Latent Dirichlet Allocation that guides the process of topic inference by these semantic anchors as seed words to the LDA. Seed words and their co-occurrences are evaluated using archetypal analysis, a geometric approximation problem that aims for finding k points that best approximate the data set's convex hull. These so called archetypes are considered as latent topics and used to guide the LDA.
We demonstrate the effectiveness of our approach using a large corpus of posts exemplarily on Twitter. Our approaches improve the topic model's qualities in terms of various quantitative metrics. Moreover, the presented algorithms used to extract seed topics can be utilized as form of lightweight topic model by themselves. Hence, our approaches create additional analytical opportunities and can help to gain a more detailed understanding of what people are talking about on social media. By using big data in terms of millions of tweets for preprocessing and fine-tuning, we enable the classification algorithm to produce topics that are very coherent to the reader.
- Serendipitous Recommendations With Knowledge GraphsHide
-
Serendipitous Recommendations With Knowledge Graphs
Oliver Baumann, Mirco Schönfeld
Recommender systems are commonly designed and evaluated with high precision and accuracy in mind. Optimising systems for these metrics alone can, however, lead to a decrease in overall collection coverage of recommended items, and over-emphasize popular content. In order to present useful suggestions to users, it has been argued that a recommender system should also provide novel and diverse items different to what the user has experienced in the past. This closely ties in with the notion of serendipity, i.e., making a surprise discovery akin to a "happy accident", that is nevertheless interesting and relevant.
We present a recommender system based on a knowledge graph of research data with serendipity, novelty and diversity in mind.
Using textual features as contextual information for vertices in the knowledge graph, we explicitly select content with a configurable element of surprise based on the user's previous experience. We are exploring an approach to extract these textual features using word-embeddings trained on highly specialized vocabularies that are similar to those expected in corpora of research data. This will enrich items' descriptions with semantically meaningful keyphrases and increase links in the knowledge graph. Ultimately, these measures not only let us determine (dis-)similarity between items, but also derive recommendations using a graph-based approach.
- Simulations as a tool in the physics of fluids and soft matterHide
-
Simulations as a tool in the physics of fluids and soft matter
Michael Wilczek
Our group focuses on the investigation of the physics of fluids and soft matter. Our research covers a range of scales, from microscopic bacterial flows to turbulence in the atmosphere. Simulations play an important role in informing theory and developing models. Therefore, high-performance computing, analysis of large-scale datasets as well as scientific visualization take a central place in our work. This poster showcases some of our recent work in the context of digital science.
- sketchometry - innovative human-computer interactionHide
-
sketchometry - innovative human-computer interaction
Carsten Miller, Volker Ulm, Andreas Walter, Alfred Wassermann
sketchometry (https://sketchometry.org) is a digital mathematics notebook for highschools, i.e. it is an interactive construction and exploration tool for plane Euclidean geometry and calculus. Since it is aimed to be used mainly on smartphones and tablets, sketchometry introduces innovative strategies for human-computer interaction in learning software. Basic elements like points, circles and lines can be sketched on the screen with fingers, mouse or pen. More complex operations like bisecting angles or constructing perpendicular lines can be achieved with intuitive gestures. sketchometry identifies these sketches and gestures with a machine-learning approach and generates an exact figure. This allows the students to explore these constructions in a very natural way by dragging, rotating and manipulating the geometric objects.
sketchometry is implemented in JavaScript and runs on client side in a web browser. This means, the sketch recognition is completely done using the limited computational resources of the web client without communication to any server. The mathematics behind this approach consists of computation of angles in a high-dimensional space and an efficient corner-finding algorithm.
sketchometry is free to use, runs on all smartphones, tablets or desktop computers, and is developed at the Chair of Mathematics and Didactics and the "Center for Mobile Learning with Digital Technology" at the University of Bayreuth.
- Smart Equipment, from sensors to data analyticsHide
-
Smart Equipment, from sensors to data analytics
Franz Konstantin Fuss, Yehuda Weizman
The expertise in Smart Equipment (sports, medical, defence) at the Chair of Biomechanics spans the range from sensor development, over electronics, data transfer, data processing, and data analytics, to discovery of new diagnostics and performance parameters, and biofeedback intervention, for research purposes and product development.
Our smart products (and their application and impact) are: climbing holds and walls (performance diagnostics, improvement of training), oar blades (hydrostatic and -dynamic pressure while rowing), 10-pin bowling ball (performance diagnostics, improvement of training), world's first smart cricket ball (performance diagnostics, improvement of training, identification of delivery; contribution to the 2019 World Cup win), baseball (performance diagnostics), AFL and rugby ball (kick precision), frisbee (flight stability diagnostics), skateboards (leg activity), swords (grip pressure), racquets(grip pressure), clubs(grip pressure), bats (grip pressure), wheelchairs (speed, energy expenditure, stroke consistency, seat pressure distribution, GPS path; contribution to 2 gold and 1 silver medals at the 2012 Paralympic Games), wind tunnels (biofeedback, optimisation of body positions; contribution to 2 World Championship gold medals in 2011 and 2013), seat mats (wheelchairs), floormats (commuter counting in Melbourne), bulletproof vehicle and helicopter armours (number and direction of impacts), smart composite structures (aerospace and automotive applications), tufts (freestream air velocity and turbulence intensity).
Highlights of this research are (in addition to athletes successfully using our products): development of highly accurate and cost-effective Graphene sensors with an extreme sensing range; discovery of skill parameters in cricket bowling; development of new signal processing methods (optimised fractal dimension method: EEG - measurement of emotional intensity, EMG - fatigue index, FoF - turbulence intensity; randomness indices: EEG - epilepsy diagnostics); sensor-less-sensing (stresses of CFRP; calculation of the centre of pressure from gyro data).
We are interested in collaboration related to extreme sensing and-or advanced signal-data processing. - Smart Wearables, from sensors to data analyticsHide
-
Smart Wearables, from sensors to data analytics
Yehuda Weizman, Franz Konstantin Fuss
The market of wearable technology is expected to be one of the largest and fastest-growing markets of the next decade. Cost-effective, personalised wide range technologies are likely to dramatically improve personal quality of life as they may offer possibilities, for (early) injury detection, physical performance monitoring, Telehealth solutions and Digital Health. Now, more than ever, the use of body-worn digital devices provides a fertile ground for countless prospective real-life settings and therefore current research and development target the possibility of conducting increasingly robust and accurate real-time estimation and/or providing real-time feedback, in different real-life settings.
The expertise in Smart Wearables (sports, medical, defence) at the Chair of Biomechanics spans the range from sensor development, over electronics, data transfer, data processing, and data analytics, to discovery of new diagnostics and performance parameters, and biofeedback intervention, for research purposes and product development.
Our smart products (and their application and impact) are: soccer boots (number of kicks, kick force, centre of pressure and sweetspot monitoring), compression garments (sports: activity monitoring, force-myography, fatigue index; medicine - venous insufficiency: activity monitoring, compliance, base pressure, pressure decline), helmet (number and magnitude of impacts; fast HIC algorithm), boxing gloves (impact force and energy), horse shoes (movement timing, lameness), pressure sensitive insoles (activity monitoring, pressure hotspots, centre-of-pressure monitoring, balance index, off-loading of diabetic ulcers, dementia diagnostics); scoliosis braces (compliance, base pressure, pressure decline, breathing frequency), bulletproof vests (number of impacts, real time impact and structural monitoring), measurement of physiological signals (HR, EEG, EMG, breathing).
The advanced signal processing methods we developed are: optimised fractal dimension method (EEG - measurement of emotional intensity, EMG - fatigue index), randomness indices (ECG-HR consistency, EEG - epilepsy diagnostics), gait analysis parameters (symmetry indices, laterality index, balance indices, lameness index).
We are interested in collaboration related to extreme sensing and-or advanced signal-data processing. - The language of inclusion and exclusion in social mediaHide
-
The language of inclusion and exclusion in social media
Annamaria Fabian, Karin Birkner
Practices in the inclusion and exclusion of minorities have been studied extensively in the social sciences, and linguistics is beginning to catch up. Many linguistic studies make use of data from digital media, itself an increasingly popular object of study in linguistics (e.g. Abel et al., 2020; Marx et al., 2020; Wright, 2020; Bubenhofer, 2017; McKeever, 2019; Wang and Taylor, 2019; De Decker and Vandekerckhove, 2017; Marx and Weidacher, 2014; Zappavigna, 2012; Crystal, 2006). Despite of having raised the awareness for the necessity of studying minority issues from a linguistic point of view, inclusive language in digital media has not been focused so far. Given this desideratum, the project addresses itself to the study of inclusion and exclusion of minorities in social media discourses. For this reason, I will gather digital data and apply methods of digital corpus linguistics. This project includes references to minorities in social media by both members and non-members of the minorities, and the linguistic and discursive aspects of any activities and policies fostering the inclusion and/or countering the exclusion of minorities. Thus, the linguistic analysis will figure out the communicative markers of inclusion, discrimination and exclusion in a digital corpus from social media (Twitter and LinkedIn). I will analyze 1. the lexicogrammar and phraseology used in the linguistic construction of minorities with respect to inclusion and exclusion in social media and 2. salient communicative strategies seeking inclusion in digital interactions. 3. This study will also bring methodological reflections on the affordances on this issue in social media. In addition, the project aims to gaining insights on effective digital linguistic methods (tools, software etc.) adaptable for the communicative analysis of data in digital media.
- The Maturity Model for the Digitalization of the Public Health Service – The Development and Application of a Tool for Assessing and Improving the Digital Maturity Level of German Public Health AgenciesHide
-

The Maturity Model for the Digitalization of the Public Health Service – The Development and Application of a Tool for Assessing and Improving the Digital Maturity Level of German Public Health Agencies
Torsten Eymann, Daniel Fürstenau, Martin Gersch, Anna Lina Kauffmann, Maria Neubauer, Doreen Schick, Nina Schlömer, Matthias Schulte-Althoff, Jeannette Stark, Laura von Welczeck
Latest, the COVID-19 crisis highlighted the key role of the Public Health Service (PHS) with its approximately 375 municipal health offices in the pandemic response. Though, in addition to a lack of human resources, the insufficient digital maturity of many public health departments posed a hurdle to effective and scalable infection reporting and contact tracing. Thus, we developed the maturity model (MM) for the digitization of health offices. The development of the MM was funded by the German Federal Ministry of Health and lasted from January 2021 until February 2022. Lately, it has been applied nationwide since the beginning of 2022 with the aim of strengthening the digitization of the PHS. The MM aims to guide public health departments step by step to increase their digital maturity to be prepared for future challenges. The MM was developed and evaluated based on a structured literature review and qualitative interviews with employees of public health departments and other experts in the public health sector, as well as in workshops and with a quantitative survey. The MM allows the measurement of digital maturity in 8 dimensions, each of which is subdivided into two to five subdimensions, and allows the measurement of digital maturity based on five maturity levels. Currently, in addition to recording the digital maturity of individual health departments, the MM also serves as a management tool for planning digitization projects. The aim is to use the MM as a basis for promoting targeted communication between the health departments to exchange best practices for the different dimensions.
- Theoretical and Computational BiochemistryHide
-
Theoretical and Computational Biochemistry
Steffen Schmidt, Jan Zoller, Rajeev R. Roy, Naveenkumar Shnmugam, G. Matthias Ullmann
In our research, we investigate the function of proteins involved in various biological energy transduction pathways using computational methods. Many of these proteins are metalloproteins or cofactor-containing proteins. To study these proteins and processes, we apply a variety of theoretical methods including continuum electrostatics calculations, molecular dynamics simulations, and quantum chemical calculations. Moreover, we develop methods to analyze and simulate the energetics and kinetics of charge and exciton transfer processes. Our work is at the interface of theoretical biophysics and biochemistry, bioinformatics and computational biology, bioinorganic chemistry, and structural biology.
- Towards AI-controlled FES-restoration of arm movements: Controlling for progressive muscular fatigue with Gaussian state-space modelsHide
-
Towards AI-controlled FES-restoration of arm movements: Controlling for progressive muscular fatigue with Gaussian state-space models
Nat Wannawas, Aldo Faisal
Reaching disability limits an individual's ability in performing daily tasks. Surface Functional Electrical Stimulation (FES) offers a non-invasive solution to restore lost ability. However, inducing desired movements using FES is still an open engineering problem. This problem is accentuated by the complexities of human arms' neuromechanics and the variations across individuals. Reinforcement Learning (RL) emerges as a promising approach to govern customised control rules for different settings. Yet, one remaining challenge of controlling FES systems for RL is unobservable muscle fatigue that progressively changes as an unknown function of the stimulation, thereby breaking the Markovian assumption of RL.
In this work, we present a method to address the unobservable muscle fatigue issue, allowing our RL controller to achieve higher control performances. Our method is based on a Gaussian State-Space Model (GSSM) that utilizes recurrent neural networks to learn Markovian state-spaces from partial observations. The GSSM is used as a filter that converts the observations into the state-space representation for RL to preserve the Markovian assumption. Here, we start with presenting the modification of the original GSSM to address an overconfident issue. We then present the interaction between RL and the modified GSSM, followed by the setup for FES control learning. We test our RL-GSSM system on a planar reaching setting in simulation using a detailed neuromechanical model. The results show that the GSSM can help improve the RL's control performance to the comparable level of the ideal case that the fatigue is observable.
- Towards an Integrated and Contextualized Research Data Management at the Cluster of Excellence Africa MultipleHide
-
Towards an Integrated and Contextualized Research Data Management at the Cluster of Excellence Africa Multiple
Cyrus Samimi, Mirco Schönfeld
In large collaborative, transdisciplinary and potentially geographically distributed research projects, joint data management enables not only the collection of research artifacts; it also fosters discovery and generation of new knowledge in the form of previously invisible interconnections between data. As such, Research Data Management (RDM) is an integral component of scientific work and collaboration covering both technical infrastructure as well as motivational capability.
A successful system for RDM offers immediate benefits to individual researchers: it helps save time finding, sharing, or editing relevant data objects, and can help prevent data loss through centralized backups. Following generations of researchers might benefit from a smartly maintained data collection. Furthermore, funding bodies increasingly require a concept for RDM as part of a grant proposal.
As such, a resilient concept for RDM should be considered part of good scientific practice. With these aspects in mind, we present the Digital Research Environment at the Cluster of Excellence Africa Multiple and outline how it can foster best practices for data collection and discovery.
Specifically, we introduce WissKI (Wissenschaftliche Kommunikationsinfrastruktur, "scientific communication-infrastructure"), the system where research data is collected and new interconnections between data items can be determined programmatically.
Using this system, the Cluster of Excellence aims to add a unique layer to the general task of RDM: We see RDM as a means to reveal novel inter- and transdisciplinary links and interconnections between researchers. With this work, we describe our integrated and contextualized RDM-system which will serve as a key component of the Digital Research Environment of the Cluster Africa Multiple.
- Towards autonomous thin film analysisHide
-
Towards autonomous thin film analysis
Fabian Eller, Eva M. Herzig
Organic semiconductors play an important role in organic electronics and are usually processed in the form of thin films. The performance of such films with a thickness between 50 to 200 nm depends strongly on the nanomorphology and nanostructure of the organic molecules within the film. In our lab we specialize on the characterization and manipulation of such thin films to maximize performance and stability. During processing many parameters influence the molecular configurations obtained during the drying of the thin film. Key for us is to access decisive parameters experimentally and obtain reliable datasets, but several of our additional challenges can benefit from the tools of the digital sciences. 1) We need to efficiently extract relevant data from large, experimentally collected datasets. 2) We need to interpret this data efficiently to act upon the outcome. Hereby we work with time-resolved spectroscopy, microscopy and reciprocal space data. Furthermore it is possible to collect additional data on the final films, while the different methods vary with complexity. 3) We need to decide which points in our parameter space are most important to sample and which measurements to use for efficient understanding of the material.
With many new materials being currently developed an efficient approach to understanding new materials is highly relevant for this field. - Twitter-Hashtag #IchBinArmutsbetroffen (#IamAffectedByPoverty) - Perspectives on Food PovertyHide
-

Twitter-Hashtag #IchBinArmutsbetroffen (#IamAffectedByPoverty) - Perspectives on Food Poverty
Tina Bartelmeß, Mirco Schönfeld, Jürgen Pfeffer
Poverty and its impact on food have become more visible since the COVID-19 pandemic and are increasingly discussed in public, e.g., on the social media platform Twitter. From May 2022, the German-language hashtag #IchBinArmutsbetroffen triggered a wave of public confession by people affected by poverty. This study examines which food-related discussions were conducted under this hashtag and what can be inferred from it about manifestations of food poverty in Germany, especially how it is experienced in its social dimension.
In November 2022, 74832 tweets with the hashtag spanning from the period of May to November 2022 were collected using the academic API of Twitter. From these, 18965 food-related tweets were identified by using a food-related dictionary. These were analysed qualitatively and descriptively. Topic structures, representations and evaluations of users tweeting about food poverty in relation to their life situation, resources and barriers were identified.
The results show that food is a key area in which poverty is perceived and experienced. 25 percent of the discussions under the hashtag are related to food. These are very diverse in terms of food-related content. They refer to both the material and social manifestations of food poverty. Different social, cultural, and mental manifestations of food poverty have been identified, which help to better describe and understand the phenomenon.
This study is an interdisciplinary study in collaboration with food sociologists and digital social scientists. The analysis of Twitter discussions provides information about the life situations and perspectives of users affected by food poverty and can be an important complement to ongoing materially oriented assessments. The findings provide an impetus for poverty and food behaviour research to consider the social aspects of food and nutrition in a stronger and more differentiated way. - Understanding and overcoming the digital health divideHide
-
Understanding and overcoming the digital health divide
Laura M. König
Digital solutions for health promotion and healthcare became popular in the last decades, which has led to an exponential rise in digital intervention research and policies being introduced to promote digital solutions for healthcare. This development was further accelerated by the COVID-19 pandemic, which required healthcare providers to seek solutions for continued care online. Technology is often presented as a solution to overcome geographical barriers and improve access to healthcare to underserved populations. However, evidence supporting these claims is sparse; in fact, research suggests that digital interventions may be less frequently used by and less effective in deprived populations. This observation is often referred to as the digital health divide.
This poster summarizes ongoing research activities in the Public Health Nutrition group that are currently carried out in collaboration with multiple national (e.g., Leibniz Science Campus Digital Public Health, Bremen) and international (e.g., University of Bath, University of Amsterdam) partners. These research activities aim (1) to quantify the extent of the digital health divide, (2) to understand its causes, and (3) to develop solutions to make digital health services more equitable. With this research, we ultimately aim to improve digital solutions for health promotion and care to improve healthcare for all. - Using language models for protein designHide
-
Using language models for protein design
Sergio Romero-Romero, Noelia Ferruz, Sabrina Wischt, Steffen Schmidt, Birte Höcker
Protein design aims to build novel proteins tailored for specific purposes, thereby holding the potential to tackle many environmental and biomedical problems. Recent progress in Transformer-based architectures has enabled the implementation of language models capable of generating text with human-like capabilities. Motivated by this success, we developed ProtGPT2, a language model trained on natural proteins that generates de novo protein sequences following the principles of natural ones. Experimental validation of a set of novel proteins generated with ProtGPT2 show that many of these are well expressed in bacterial host cells and contain the ability to fold and function as their natural counterparts highlighting the potential of such approaches for protein design.
- Using MILPs for creating robust Adversarial ExamplesHide
-
Using MILPs for creating robust Adversarial Examples
Jörg Rambau, Ronan Richter
With Deep Neural Networks (DNNs) being used in more and more fields, including applications with higher security requirements or wider social implications, there is an increasing need to study the limitations and vulnerabilities of such networks. One way to mislead a DNN and thereby potentially causing harm is the utilization of Adversarial Examples. These are inputs for the DNN, that are close to ordinary instances of one category, equipped with small changes, sometimes even invisible for the human eye, such that the DNN erroneously determines a totally different category. Such Adversarial Examples may be artificially generated to actively fool a network or they may just randomly appear in applications, for example due to noise.
One way of systematically generating Adversarial Examples for DNNs consisting of multiple layers of rectified linear units is a MILP model, as it has been proposed by Fischetti and Jo (2018). Using these global optimization techniques bears the advantage, that, on top of generating the best Adversarial Example, one can proof, that there cannot be a better one. Thus, one can guarantee, that the DNN cannot be fooled by inputs with fewer manipulations.
The goal of our research is to go one step further by developing mathematical models for generating robust Adversarial Examples. These examples cannot be ruled out by minor modifications of the DNN, e.g. by slightly more training data. This allows us to investigate the general limitations of DNNs to a greater extend, since robust Adversarial Examples are valid for a whole class of DNNs. - Utilization of biomechanical data for the development and classification of sports shoesHide
-
Utilization of biomechanical data for the development and classification of sports shoes
Tizian Scharl
Sports footwear is primarily evaluated using mechanical tests. Not only do these tests lack the consideration of the interaction between the sports equipment and the athlete, but previous studies have shown a significant discrepancy between mechanical and biomechanical footwear testing. The biomechanical approach is based on the analysis of sport-specific movements using, for example, force plates, motion capturing and inertial sensors. The goal is to characterize athletic footwear in terms of sport-specific performance, biomechanical loading, and postural stability. Based on the accelerations and ground reaction forces, shoe-dependent performance as well as the biomechanical load can be determined. Supplemented by kinematic data from motion capturing, inverse dynamics can even be used to estimate the joint forces and moments and, in a next step, the acting muscle forces to describe the load on the musculoskeletal system more precisely. Also based on the ground reaction forces, the position and movement of the center of pressure (COP) can be determined to estimate the shoe-dependent postural stability. In this context, fractal analysis of the COP data is a promising approach to complement traditional stability parameters such as the average velocity of the center of pressure.
The main challenges are the acquisition, processing and analysis of large, heterogeneous data sets and the separation between subject- and object-specific influencing factors. By matching with the subjective perception in the different categories, the customer-relevant biomechanical variables will be determined and combined to summary criteria. For example, Knowledge Discovery in Databases (KDD) methods are used to uncover complex relationships between biomechanical variables and the perceived performance, load reduction and stability. In the context of shoe development, the determined criteria can serve as optimization parameters. In addition, the biomechanical data can be used for simulations e.g., as boundary conditions for the mechanical simulation of the sports shoe using finite element analysis.