Posters from 2nd BayLDS-Day
- A Path Following Approach for Acoustic Levitation Displays Hide
-
A Path Following Approach for Acoustic Levitation Displays
Viktorija Paneva, Arthur Fleig, Diego Martínez Plasencia, Timm Faulwasser, Jörg Müller
Acoustic levitation displays use ultrasonic waves to trap millimetre-sized particles in mid-air. Recent technological advancements allowed us to move the levitated particles at very high speeds. This was crucial for developing Persistence of Vision displays using acoustic trapping, that is, displays that present visual content within the integration interval of human eyes of around 0.1s. However, the problem of how to control this dynamical system (i.e., how to apply the acoustic force to obtain the desired particle movement), as to follow a predetermined path in minimum time was largely unsolved until now. In our research, we develop an automated optimization pipeline that produces physically feasible, time-optimal control inputs that take into account the trap-particle dynamics and allow the rendering of generic volumetric content on acoustic levitation displays, using a path-following approach.
- ABBA - AI for Business | Business for AI Hide
-
ABBA - AI for Business | Business for AI
Yorck Zisgen, Agnes Koschmider
The use of Artificial Intelligence (AI) in business requires specific competencies. In addition to technical expertise, the business sector needs individuals with the ability to evaluate technical systems, integrate them into operational processes, work environments, products, and services, and consistently control them. This bridging role primarily falls on business economists as key operational decision-makers. The target audience of the joint project includes business administration and related business study programs (business informatics, business engineering, etc.), which together constitute about 22% of students at German universities.
The goals of ABBA – AI for Business | Business for AI include the development and provision of a modular teaching kit for AI, offering business students scientifically founded and practically relevant interdisciplinary AI competencies. The modular kit supports teaching for bachelor's, master's, executive master's, and doctoral students at universities and universities of applied sciences (HAW). It consists of three pillars: (1) AI-related teaching content tailored to the students' background, skills, interests, and relevant professional requirements. New, high-quality didactic content is created, and established Open Education Resources are utilized. (2) A hands-on AI learning factory is established collaboratively with students. (3) An organizational and technical exchange platform is created, allowing universities, industry partners, and students to connect, harness synergies, and efficiently build competencies.
The consortium project brings together eleven applicants from three universities and one HAW from three federal states, united by a focus on AI competencies for business students. Content and formats are collaboratively developed, mutually utilized, and made publicly accessible. Compared to individual development, this strengthens the breadth and depth of the offering, substantially enhancing the efficiency and quality of teaching.
Despite being one of the largest study disciplines in Germany, business students are inadequately prepared for the novel, complex issues and changed job responsibilities related to the spread of AI. The project aims to address this educational gap by providing high-quality teaching to prepare business students for new management requirements in the AI field. The existing AI teaching offerings at the participating universities are currently limited. The project seeks to expand the rudimentary AI teaching with a business focus into a flagship program, providing students with the best possible preparation for the practical implementation of AI.
The strategic use of AI as a key technology for the future is crucial for efficient business processes and innovative products and services. The role of business economists is central in promoting the use of AI in business, acting as decision-makers, organization designers, leaders of relevant units and teams, and coordinators of AI initiatives. The required skill set is becoming increasingly interdisciplinary, and business economists are confronted not only with traditional business questions but also with technological ones. A well-informed knowledge profile in AI is essential for making informed decisions and contributing to the successful implementation of AI in practice. The project aims to bridge this knowledge gap.
- Adaptive Step Sizes for Preconditioned Stochastic Gradient Descent Hide
-
Adaptive Step Sizes for Preconditioned Stochastic Gradient Descent
Frederik Köhne, Leonie Kreis, Anton Schiela, Roland Herzog
The choice of the step size (or learning rate) in stochastic optimization algorithms, such as stochastic gradient descent, plays a central role in the training of machine learning models. Both theoretical investigations and empirical analyses emphasize that an optimal step size not only requires taking into account the nonlinearity of the underlying problem, but also relies on accounting for the local variance within the search directions. In this presentation, we introduce a novel method capable of estimating these fundamental quantities and subsequently using these estimates to derive an adaptive step size for stochastic gradient descent. Our proposed approach leads to a nearly hyperparameter-free variant of stochastic gradient descent. We provide theoretical convergence analyses in the special case of stochastic quadratic, strongly convex problems. In addition, we perform numerical experiments focusing on classical image classification tasks. Remarkably, our algorithm exhibits truly problem-adaptive behavior when applied to these problems that exceed theoretical boundaries. Moreover, our framework facilitates the potential incorporation of a preconditioner, thereby enabling the implementation of adaptive step sizes for stochastic second-order optimization methods.
- Advancement in statistical modelling for spatial air pollution prediction Hide
-
Advancement in statistical modelling for spatial air pollution prediction
Meng Lu
Poor ambient air quality represents one of the largest environmental risks to public health.
Quantification of long-term personal exposures over a large population is required in epidemiological studies and risk assessment and abatement. This calls for detailed spatial maps of air pollution over a long time period. Statistical modelling, which commonly analyses the relationships between air pollution observations and relevant geospatial features, arose in recent years due to the tremendous increase of available predictors. The application of a large array of statistical modelling methods (including machine learning) contribute to rich literature but problems persist in relatively low prediction accuracy and uncertainty assessment (including model validation). Also, very few studies have evaluated or compared different methods comprehensively in terms of prediction accuracy, efficiency, interpretation, and uncertainty quantification. This presentation hits the target of the BayLDS day in both introducing advanced spatial statistical methods and the applications. I will introduce my recent study which compares geostatistical and other models. The INLA (Integrated Nested Laplace Approximation) method which is applied to accelerate geostatistical model computation will also be briefly introduced and discussed. Lastly, through a recent experiment using long-term dense mobile sensing measurements, we will have a close look at the performance of different kinds of statistical models in various air pollution sampling scenarios and discuss what is missing in recent air pollution modelling studies.
- AI in Data-driven Business Process Management Hide
-
AI in Data-driven Business Process Management
Stefan Jablonski, Lars Ackermann, Julian Neuberger, Martin Käppel
Business process management (BPM) is concerned with the goal-oriented design, execution, analysis, and continuous improvement of processes within an organization. Companies and enterprises achieve higher performance when they proactively oversee their workflows, from inception to completion. Realizing the hidden potential in company data, such as event logs, employee documentation, or emails, is crucial to maintaining an edge in performance. Unlocking this potential was mainly enabled by rapid advances in machine learning and artificial intelligence.
Our research group is dedicated to harnessing these advances in two promising areas of BPM, i.e., predictive business process monitoring and automatic extraction of process models from natural language data. Predictive business process monitoring aims to predict how a running process instance will unfold up to its completion, including predicting next steps, expected outcomes, remaining time, and monitoring compliance requirements. Extracting business process models from natural language text enables rapid adoption of BPM in companies of any size. Additionally, we research the challenge of data scarcity in both subfields, particularly prevalent in small and medium-sized enterprises. To tackle this issue, we are currently leveraging data augmentation and transfer learning methods to overcome the limitations of insufficient quantitative data.
In addition to scientific collaboration, we are also interested in cooperation with industry (e.g. contract work, joint projects). A major challenge for our research at present is the limited availability of real-world data. We are also currently looking for cooperation partners with whom we can test our approaches in practice. Since the methods we develop and use (e.g. ChatGPT, our own deep learning architectures) is not limited to BPM, we are also interested in discussing their application in new areas.
- Application of Bayesian optimization to polymer engineering problems Hide
-
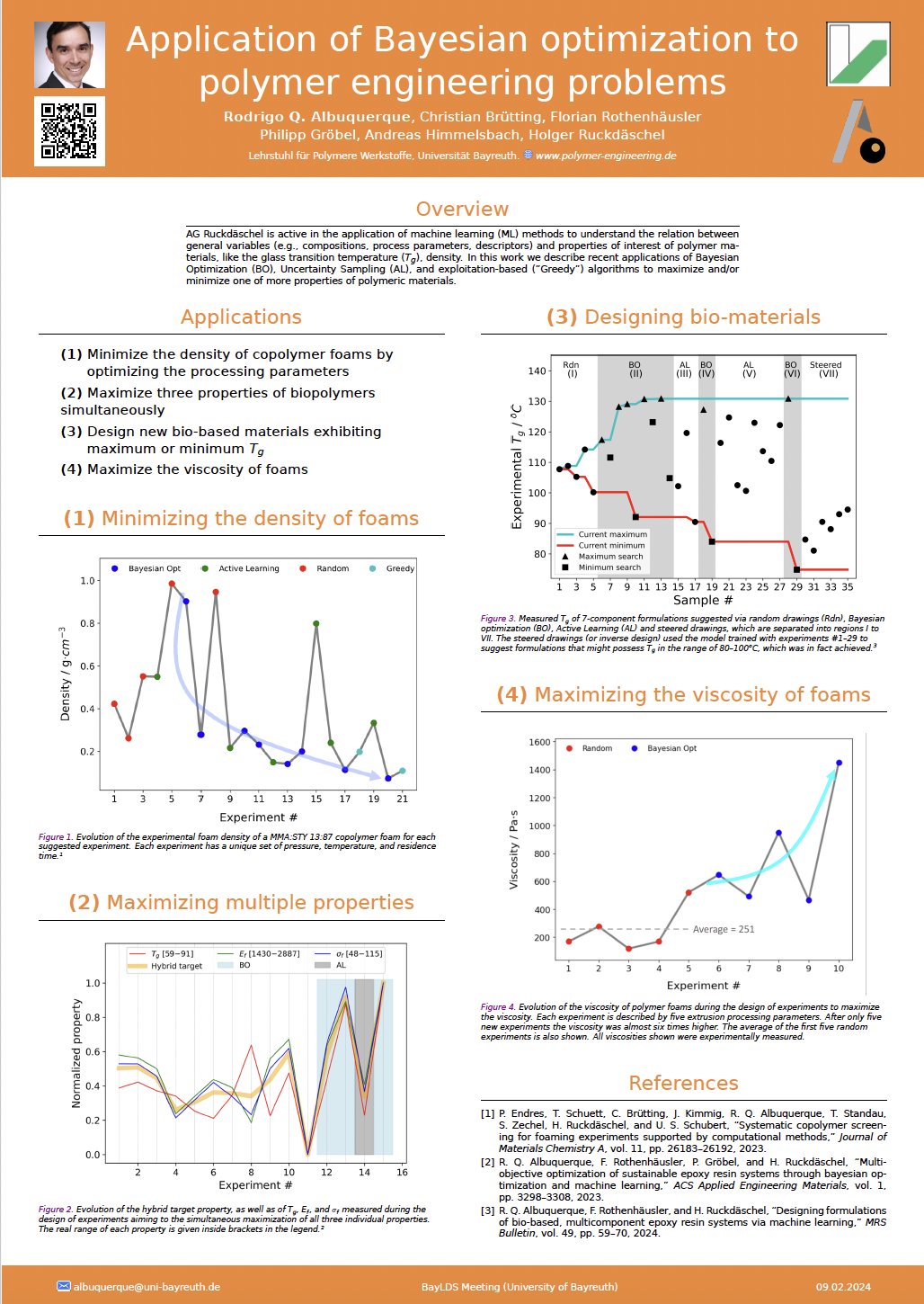

Application of Bayesian optimization to polymer engineering problems
R. Q. Albuquerque, F. Rothenhäusler, C. Brütting, P. Groebel, H. Ruckdäschel
Optimizing formulations or processing parameters to develop novel biopolymers or to improve the property of existing ones is in general a challenge, especially when many parameters must be simultaneously optimized. Bayesian optimization (BO) is a machine learning (ML)-based technique from which multiple parameters can be simultaneously optimized aiming at maximizing and/or minimizing one or more target properties like the glass transition temperature (Tg), the foam density, among others. During the active learning rounds, a Gaussian Processes (GP) model is trained with the current dataset, then new parameters are suggested and subsequently the corresponding experiment is performed, from where a new experimental target property is measured and in turn used to update the GP model again. In this work, we show some examples of using the BO technique. We minimize the density of PLA foams [1] by optimizing three processing parameters (pressure, temperature and residence time). We maximize/minimize Tg of bio-based epoxy resin systems [2] by optimizing the 7D composition (seven aminoacids as hardeners). Finally, we simultaneously maximize three target properties (Tg, flexural modulus and flexural strength) by optimizing the composition of an eight-component biobased epoxy resin system [3]. After the dataset is large enough, ML models are trained to perform predictions on customized formulations or processing parameters, as well as to perform inverse design.
[1] P. Endres, et al., Journal of Materials Chemistry A (2023), DOI: 10.1039/d3ta06062d.
[2] R. Q. Albuquerque, et al., MRS Bulletin (2024), https://doi.org/10.1557/s43577-023-00504–9.
[3] R. Q. Albuquerque, et al., ACS Applied Engineering Materials (2023), in press.
- Are current fire dynamics in temperate forests signaling a novel fire regime? - Using Artificial Intelligence for forest monitoring and prediction of fire events (KIWA) Hide
-
Are current fire dynamics in temperate forests signaling a novel fire regime? - Using Artificial Intelligence for forest monitoring and prediction of fire events (KIWA)
Leonardos Leonardos, Carl Beierkuhnlein, Wolfgang Dorner, Karim Garri, Tobias Heuser, Peter Hofmann, Christopher Shatto, Peter Ulfig, Anke Jentsch
European forests are becoming increasingly vulnerable to emerging fire regimes. The shifting disturbance regime, and its magnitude, duration, and frequency, are poorly understood. The consequences for biodiversity, habitat degradation, and carbon budgets remain unclear. Novel ways of dealing with forest fire events are needed, in order to prepare for such events and safeguard future biodiversity. Modelling approaches based on artificial intelligence (AI) are a promising tool for early fire detection.
Here, we investigate the shifting fire regime in Germany by using remote sensing to identify the temporal patterns of canopy browning - a typical fire-precondition in terms of fuel quality -, and by carrying out field surveys to record forest architecture and composition. Then, we integrate remotely sensed-, field- and climate data in an AI model for forest monitoring, and fire risk prediction. Thereby, we tackle questions, such as: 1) What are the changing ecological pre-conditions that produce fire and alter ecosystem trajectories? 2) Why are some temperate forest types (differing by species composition, stand structure) more prone to fire than others?
Our research contributes to the understanding of changing fire regimes in the Anthropocene, risk to fire, and new ways of forest fire risk management for ecosystem resilience.
- Artificial Intelligence Tools for Teaching Materials Science Hide
-
Artificial Intelligence Tools for Teaching Materials Science
Katharina Peipp, Rodrigo Albuquerque, Holger Ruckdäschel, and Christopher Kuenneth
As part of a statewide initiative in Bavaria, AI tutors are trained to help integrating artificial intelligence methods in teaching. At the Kuenneth (computational materials science) research group, AI tutors help students to apply AI in materials science, support integrating AI in teaching, and merge knowledge from various materials-related lectures using AI. The overall aim is to showcase how AI can be used in materials science research.
AI tools are also utilized to create student quizzes and exercises for recapitualing the content of the lectures. In the lecture "Python and data tools for non-programmers", students are shown how AI tools, specifically large language models, help with the creation, debugging and explanation of Python code. In the lectures "Numerical Modelling in Material Science" and "Machine Learning in Material Science", we plan enrich slides with AI created content such as text, pictures, and exercises that improve the learning experience and facilitate knowledge conservation.
We also aim to create an understanding among students and lecturers for the application of AI in materials science and teaching. The integration of AI in teaching should not only improve the learning success of students but also democratize AI methods and imply the importance of AI in materials science.
- Automated identification of cricket deliveries with a smart cricket ball Hide
-
Automated identification of cricket deliveries with a smart cricket ball
Franz Konstantin Fuss, Batdelger Doljin, René E. D. Ferdinands
The development of the world's first cricket ball by Fuss and coworkers dates back to the end of 2011. The ball includes three high-speed gyros that can record angular velocities of up to 20,000 degrees per second. The angular velocity is measured at 815 Hz. The data are transmitted wirelessly to a laptop or mobile phone and the ball's battery is charged inductively. Cricket spin bowling deliveries are divided into finger spin and wrist spin; Each of the two categories is further divided into: backspin, backsidespin, sidespin, topsidespin, topspin and swerve. The challenge of this project is to identify the correct delivery based solely on gyroscopic data. Angular velocity is measured with respect to the ball coordinate system (BCS), while the different deliveries are identified using the angular velocity vector “W” (spin axis) in the global coordinate system (GCS). First, the BCS is statically aligned with the GCS so that the positive x-axis points in the direction of the intended ball impact point on the pitch. Then the ball is removed from its static position and the BCS is aligned on the hand (index finger on the positive x-axis and the positive z-axis to the right, regardless of the bowler's handedness). This orientation allows the distinction between finger spin (negative Z component of angular velocity) and wrist spin (positive Z component). The spin axis is transferred from the BCS to the GCS by continuously rotating the GCS around the instantaneous W vector (in the BCS), namely by the magnitude of the instantaneous angular velocity divided by the sampling frequency. After each completed rotation step, the rotated GCS was rotated back to its original and initial position along with the instantaneous W vector. The specific delivery was identified based on the yaw and pitch angles of the W vector in the GCS. We tested 31 deliveries at various combinations of yaw and pitch angles for finger spin and wrist spin. The Smart Ball was equipped with 3 reflective markers for additional identification of deliveries using a motion analysis system. The marker triad was solidified with a spatial filter to accurately calculate the helix axis (W vector) in the GCS. The delivery data (yaw and pitch angles of the W vector) obtained from the smart ball and motion analysis system were tested for agreement with Band-Altman diagrams. The angular data agreed well with only one of the 31 deliveries outside the 95% CI for each of the yaw and pitch datasets. From the type of delivery data, 55% of the deliveries were correctly detected in the topspin-to-backspin range; and 45% were in the adjacent delivery zone (error of 12.5%). In the swerve range, 90% were recognised correctly and 10% were in the adjacent delivery zone (error of 20%). The Smart Ball method for identifying the correct delivery is sufficiently accurate if a delivery is tested at least 6 times (1 over). We developed a special plot to visualise the deliveries bowled on an equirectangular projection of the ball's surface.
- Blueprint for ChatGPT Usage Guidelines Hide
-
Blueprint for ChatGPT Usage Guidelines
Claudius Budcke, Alexa Gragnato, Enes Gümüssoy, Salomé Kalessi, Felix Klingert, Josephine Görk
The initiative "KI-Tutor:innen Bayern", led by ProLehre at the Technical University of Munich and the ZHL, aims to integrate Artificial Intelligence harmoniously and beneficially into teaching and learning processes. With the involvement of 50 AI tutors from various Bavarian universities, the aim is to optimize teaching and learning methods through the use of the latest AI technologies, while at the same time creating a framework that minimizes potential dangers.
Educators and students are currently in midst of a technological revolution that has a noticeable impact on teaching and learning methods. In light of this rapid change, it is essential to develop guidelines promptly. These should provide students with security when using AI tools like ChatGPT. However, as uniform regulations are still in development, it currently falls to the teaching staff to determine the extent of AI tool usage in their courses. This individual decision-making power can specifically consider the unique requirements of each subject area and the implications arising from the use of ChatGPT.
The project "Blueprint for ChatGPT Usage Guidelines" by AI Tutors from Bayreuth and Passau aims to develop a form that helps educators quickly gain an overview of the possible uses of ChatGPT for students. Through checkboxes and text fields, educators can define the scope of what is allowed in their respective subjects. The result is a PDF form in which teaching staff can indicate which applications of ChatGPT are permissible for their students and which are not. Ideally, this form can then serve as a guide for students to understand the dos and don'ts.
The project is still in the early stages of its development. However, we would like to take this opportunity to present our progress at the BayLDS Day 2024 and engage in dialogue with interested parties. This will allow us to collect valuable feedback and better tailor our product to the needs of the teaching staff.
- Building a Sustainable Research Data Management Systems for Reconfiguring African Studies Hide
-
Building a Sustainable Research Data Management Systems for Reconfiguring African Studies
Jae Sook Cheong, Neeraj Thandayan Viswajith, Marisol Vázquez Llamas, Anke Schürer-Ries, Mirco Schönfeld, Cyrus Samimi Cyrus Samimi
Today’s societies are pervasively influenced by technologies such as Artificial Intelligence (exemplified by ChatGPT), the metaverse, blockchain technology, and virtual reality/augmented reality. Despite this technological prevalence, vast amounts of data remain inadequately managed, un-digitized, or unregistered within digital systems, creating a significant gap at various levels and across diverse sectors, cultures, and countries. Narrowing this gap is an important outcome sought by the Africa Multiple Project.
The Research Data Management System (RDMS), which utilizes the Fluid Ontology concept to interconnect data, serves as a pivotal medium in reconfiguring African Studies in the Africa Multiple Project. This platform aims to establish data ownership for each African Cluster Center (ACC) and other partners, foster best practices in Research Data Management, and encourage active collaboration among researchers. By securing data while ensuring openness, the system strives to enhance the visibility of each research group within the Cluster, ultimately identifying popular topics, research questions, and unexplored areas. This collaborative effort seeks to transform perspectives on research within African studies.
This presentation will delve into how the aforementioned objectives are realized through WissKI@UBT and RDMSs across all ACCs. It will elucidate the planning and execution of data intake with various automation, as well as consultations to promote data literacy. Additionally, the discussion will encompass challenges encountered at the digital system level and the promotion of good research data management practices.
- Chair of Economathematics: Showcase Discrete Optimization Hide
-
Chair of Economathematics: Showcase Discrete Optimization
Jörg Rambau
- Collective variables in complex systems: molecular dynamics, spreading processes on networks, and fluid dynamics Hide
-
Collective variables in complex systems: molecular dynamics, spreading processes on networks, and fluid dynamics
Péter Koltai
Today’s societies are pervasively influenced by technologies such as Artificial Intelligence (exemplified by ChatGPT), the metaverse, blockchain technology, and virtual reality/augmented reality. Despite this technological prevalence, vast amounts of data remain inadequately managed, un-digitized, or unregistered within digital systems, creating a significant gap at various levels and across diverse sectors, cultures, and countries. Narrowing this gap is an important outcome sought by the Africa Multiple Project.
The Research Data Management System (RDMS), which utilizes the Fluid Ontology concept to interconnect data, serves as a pivotal medium in reconfiguring African Studies in the Africa Multiple Project. This platform aims to establish data ownership for each African Cluster Center (ACC) and other partners, foster best practices in Research Data Management, and encourage active collaboration among researchers. By securing data while ensuring openness, the system strives to enhance the visibility of each research group within the Cluster, ultimately identifying popular topics, research questions, and unexplored areas. This collaborative effort seeks to transform perspectives on research within African studies.
This presentation will delve into how the aforementioned objectives are realized through WissKI@UBT and RDMSs across all ACCs. It will elucidate the planning and execution of data intake with various automation, as well as consultations to promote data literacy. Additionally, the discussion will encompass challenges encountered at the digital system level and the promotion of good research data management practices.
- Computer-Mediated Communication for Inclusion: Corpus Analysis on Disability & Inclusion on Social Media in digital societies Hide
-
Computer-Mediated Communication for Inclusion: Corpus Analysis on Disability & Inclusion on Social Media in digital societies
Dr. Annamária Fábián
Computer-Mediated Communication for Inclusion: Corpus Analysis on Disability & Inclusion on Social Media in digital societies
Dr. Annamária Fábián – Department of German Linguistics/University of Bayreuth – Bavarian Research Institute for Digital Transformation
Keywords: Computer-Mediated Communication, Diversity & Inclusion in digital Societies, Disability-Related Inclusion
This project examines digital language use concerning disability and inclusion – edited by people with and without disability – on social media. For this, a Twitter corpus comprising of 7.000.000 tokens is used for the analysis. The corpus consists of German tweets published between 2007 – 2023 under the hashtags `inclusion´ and ´disability´ in German, English and French. This linguistic examination provides valuable insights into the lexicon concerning disability and inclusion as well as the co-occurrences of the lexical units. Besides several studies focus on language and discrimination, I analyse a corpus with focus on inclusion as it is key to societies to get an overview not only on linguistic phenomenon on discrimination and exclusion but also inclusion. Hence, this study encompasses a quantitative and qualitative lexicon analysis with Software for Corpus Linguistics, which is, methodologically and also regarding the topic of this issue, a valuable contribution to applied language and communication studies but also to life sciences and the humanities. In addition, also qualitative research methods are used for further analysis on the communication of diversity and inclusion.
- Data4Collar Hide
-
Data4Collar
Dominic Langhammer, Agnes Koschmider
Shear-cutting and collar-forming (also known as hole-flanging or flange forming) is a sheet metal forming processes chain which is intertwined in the industrial production of many functional components. Flanged holes can be produced in any shape desired as bearing, fixturing or spacing elements and can be found on almost each sheet metal component. The collar-forming process usually begins with a shear-cutting step to create a pilot hole, which subsequently is drawn into a flange. This hole often is the reason for material failure in the form of edge crack formation, making the resulting product useless. This may also occur after the part has been implemented in the final product (e.g., car door). Since these parts are produced in high volume, reducing the number of defective parts may have a significant economic relevance.
The extreme complexity and non-linearity of the underlying physical behavior during the collar-forming process and its dependence on stochastically fluctuating process variables such as tool wear, material batch variations and sheet thickness, prevent the reliable prediction of edge cracks using analytical mathematical models or finite-element (FE) simulations. Understanding this process and thereby reducing the amount of damaged product requires a more stochastic data driven approach. The main object of interest in our research is the force-displacement curve, which contains characteristic of the entire forming process. Both, shear-cutting and collar-forming yield such a curve and they can also be generated with FE simulations. We will use these curves and additional sensor and image data in combination with statistical, machine learning (ML) and process mining techniques to develop an exact digital mapping of the process chain consisting of shear cutting and flange-forming. On this basis, it will be possible to optimize the tools involved in such a way that edge cracks will no longer or only rarely occur in the future reducing material and monetary waste.
- Detecting voids of knowledge and measurable data in a multidisciplinary digital environment and the aspect of fluid ontologies Hide
-
Detecting voids of knowledge and measurable data in a multidisciplinary digital environment and the aspect of fluid ontologies
Alexandra Kuhnke, Oliver Baumann, Wynand van der Walt, Mirco Schönfeld
To provide the next generation of researchers with knowledge and research results, there is a need to store data into a database observing the FAIR principles. Therefore, experts transfer their knowledge and research results into the latter by often linking taxonomies and ontologies. For various reasons, however, the existing taxonomies and ontologies are not always sufficient to describe research results. This provokes a need to know which aspects within a database are sufficient or insufficient defined and does the additional embedding and cross-linking of various ontologies and taxonomies decrease the amount of insufficient defined data? If we agree on ontologies defined as a formal, explicit specification of a shared conceptualization, then, there is a need to widen the understanding of ontology. It is valuable to know how the aspect of fluidity affects static knowledge transfer.
To detect the mentioned gaps and to describe existing voids in subject to interdisciplinary knowledge exchange, it is essential to develop a digital method. The purpose of the contribution is to introduce and discuss a concept and a digital method to detect data and knowledge gaps within a multidisciplinary digital environment. This digital method could affect future research and support resource-efficiency.
- Development of a Cost-Effective Smart Saddle Mat for Bike Fitting: A Comprehensive Performance Measurement Study Hide
-
Development of a Cost-Effective Smart Saddle Mat for Bike Fitting: A Comprehensive Performance Measurement Study
Yehuda Weizman, Julia Rizo-Albero, Franz Konstantin Fuss
undefinedSensor saddle mat for bike fitting is crucial, as precise saddle sensor data plays a pivotal role in understanding pressure distribution and centre of pressure variability, directly correlating with discomfort levels during cycling. Current commercially available pressure measuring mats used in bike fitting, such as Novel, Medilogic, GebioMized, and Tekscan, offer high sensor resolution but are often prohibitively expensive. Beyond assessing pressure distribution on the saddle, understanding the movement of the centre of pressure (COP) is crucial, as its variability correlates with discomfort levels during cycling. This study aims to develop a cost-effective smart saddle mat and evaluate its applicability in measuring performance parameters.
The smart saddle mat was designed with eight piezoresistive pressure sensors, each with an equal area of 3350 mm². Data acquisition was performed to collect eight pressure sensor data, calibrated by a material testing machine, and testing was conducted on a Selle Royal seat mounted on a racing bike. Trials were conducted with three participants, four saddles, both normal and cycling shoes, under three saddle tilts: horizontal (0°), forward tilt (+10°), and backward tilt (–10°). Cadence was also calculated from the right-left pressure differential and the fluctuations in the centre of pressure (COP) during the trials.
The total load on the seat varied with different inclinations: 315 N at 0°, 311 N at +10°, and 302 N at –10°, representing approximately 51% of body weight ± 2%. Pressure distribution patterns showed that when the seat was horizontal (0°), the front part of the seat experienced higher pressure than the rear. As the seat inclined backward, front and rear pressures decreased and increased, respectively. Forward tilt values fell between those of 0° and –10°. COP position mirrored seat tilt, with front, middle, and rear COP positions at 0°, +10°, and –10°, respectively. Analysis revealed distinct COPy movement spikes during acceleration, which diminished during constant speed. COPx exhibited a cyclic pattern with varying amplitude and frequency, with sensors 7 and 3 values serving a similar purpose.
Accurate cadence and speed data were obtained, revealing variations in the centre of pressure (COP) and pressure distributions among different tilts, saddles, and participants.
In conclusion, despite a limited number of sensors, the smart saddle mat captured notable pressure changes, particularly with sensors 3 and 7. These parameters aided cadence calculation and identifying intensity peaks during cycling. The study observed increased COP variability with a backward-tilted seat, indicative of discomfort. The calculated seat load aligned with prior findings, affirming the mat's reliability. Measuring saddle pressure proves beneficial for optimizing bike adjustments and enhancing sporting performance. The cost-effective design positions the smart saddle mat as a practical tool for potential adoption in bike fitting. It emerges as a useful asset for optimizing bike fitting and sports performance, providing valuable data on pressure dynamics and rider discomfort. The saddle mat design underscores its accessibility, highlighting the broader significance of integrating smart equipment, sensors, and data processing in sports science for improved training approaches.
- Dietary Norms in Social Media Discourses: The case of #Balletnutrition on Instagram Hide
-
Dietary Norms in Social Media Discourses: The case of #Balletnutrition on Instagram
Constanze Betz, Tina Bartelmeß
This research investigates the dynamics of communication surrounding eating within the Instagram hashtag #balletnutrition. Nutrition is a critical issue in professional dance, with seemingly constantly reproduced dietary norms that are closely associated with dancers' performance and physical appearance. The primary objective of this analysis is to discern how various posting roles within the digital discourse contribute to shaping the discourse on dancers’ diets, based on role-specific perceptions, and to identify prevalent eating-related topics and reproduced norms within the discourse.
Employing a mixed methods discourse analytical approach, data sourced in approximately 2000 posts from the social media platform Instagram is collected, post roles and topics identified and quantitatively charted and topics and eating related norms inductively reconstructed.
Preliminary results show that most posts take a professional stance and do not represent personal viewpoints, as is generally presumed in research on food communication on social media platforms. Notably, certain posting roles such as trainers and dietitians, alongside specific educational themes, prominently dominate the discourse surrounding the hashtag. Compared to other dietary discourses on social media, these communicators deliberately take an empowering stance to deconstruct debatable dietary norms within the world of ballet.
The results show that nutrition in professional dance is a topic that is attributed relevance by professional actors, especially from the perspective of empowerment and health promotion, and that social media platforms offer these actors a digital space for cultural entrepreneurship to challenge traditional diet-related norms in the discourse on ballet nutrition.
Keywords: social media, Instagram, #balletnutrition, posting roles, themes, food discourse, eating norms
- Digital Science in histological analysis Hide
-
Digital Science in histological analysis
Janin Henkel-Oberländer, Jörg Müller, Sonja Kuipers, Brit-Maren Schjeide
Histological staining and immunohistochemistry assays are widely used methods in (patho)biochemistry and (patho)physiology to investigate the general morphology as well as the expression pattern of specific proteins in animal and human tissues. Antigens will be tagged with specific antibody-antibody reactions, which can be visualized by chromogens or fluorophores in high-resolution microscopy. As a result, different staining pattern can be visualized in microscopical images. While an all-or-nothing-signal is easy to quantify but rare, scientists are often faced with the problem that staining analysis of complex tissues shows different density and distribution patterns of the signal within the tissue slide or that staining background is heterogenous within the samples.
Digital Science might be able to (partly) solve this problem and will open new possibilities to a fast and objective evaluation of expression pattern of specific structures in histological tissue analysis.
In a first approach, tissue samples from mice liver stained with an antibody against the macrophage surface marker F4/80 were analyzed. Resident macrophages are located around vessels and staining signal will be distributed in isolated small areas equally in healthy liver tissue. In liver tissue of mice fed a high-fat high-cholesterol diet for 20 weeks, metabolic dysfunction associated fatty liver disease (MAFLD) was diagnosed, which is characterized by lipid accumulation visible as small to large lipid droplets heterogenous distributed in the tissue, tissue inflammation visible as infiltration of F4/80-positive cells, as well as beginning fibrosis visible as morphological changes and matrix accumulations. In fact, diet-induced MAFLD increased liver weight and volume. In addition, cell composition changed due to macrophage infiltration. As a result of this, histological images of a diseased liver compared to a healthy liver contain less (but hypertrophic and lipid droplet-filled) hepatocytes but more F4/80-positive macrophages. Furthermore, subtypes of macrophages accumulate specifically around fat-laden hepatocytes. The challenge in analysis was to quantify this subtype of macrophages in diseased versus healthy liver.
First results allow detailed characterization of lipid droplet sizes. In addition, staining density of F4/80 antigens were quantified according to their density and localization around larger lipid droplets allowing to distinguish between resident and infiltrated macrophages. This analysis helps to quantify the grade of steatosis and tissue inflammation in liver samples of diet-induced fatty liver disease and allows a better comparison of intervention groups than the quantification methods used before.
- Discrete structures, algorithms, and applications Hide
-
Discrete structures, algorithms, and applications
Sascha Kurz
- Dynamic models, stats, and forest ecology Hide
-
Dynamic models, stats, and forest ecology
Lisa Hülsmann, Leonie Gass, Lukas Heiland
In the group Ecosystem Analysis and Simulation (EASI lab), we are interested in the development, evaluation, and synthesis of ecological theories to understand the dynamics of ecosystems and biodiversity in space and time. Our core research focuses on plant systems, especially forests, which we study through the lens of demography, using growth, mortality, and regeneration/birth rates, to understand the mechanisms that influence the form and functioning of ecosystems and predict their response to environmental drivers such as climate change.
We approach these questions using a combination of quantitative and theoretical techniques, especially statistical and simulation models. One of the strategies that we apply is model data integration, as it allows to answer complex ecological questions and make more robust projections into the future in an era of Big Data. For example, we use Bayesian approaches to connect dynamic forest models with various data sources and types that differ in their temporal and spatial resolution and that have been measured at different ecological levels, e.g., at the process, individual, or population level. An example of how we apply statistical approaches for robust ecological inference is a current project on conspecific negative density dependence (CNDD), where we use a combination of advanced statistical models backed-up with dynamic simulations, null models, and meta-analyses to assess the role of CNDD for local community composition and large-scale diversity patterns in forests.
Underlying all these efforts, and ultimately enabling scientific synthesis, are large ecological datasets from multiple sources. Therefore, we pay special attention to data curation and homogenization, as they are integral to the reproducibility and long-term use of data.
- Exploring new business ventures to facilitate product diffusion in retail: Innovation diffusion through mobile retail Hide
-
Exploring new business ventures to facilitate product diffusion in retail: Innovation diffusion through mobile retail
Florian Cramer, Christian Fikar
The recognition of local actors as pivotal agents for sustainability in food chains has grown significantly. However, despite the support of some enterprises from venture capital and media, numerous micro-, small-, and medium-sized enterprises (MSMEs) in the food industry encounter challenges related to product diffusion and market reach. As a consequence, numerous innovative products originating from startups without substantial support encounter difficulties in reaching consumers, potentially facing marginalization. Our research delves into this initial phase of product diffusion and examines alternative distribution channels by comparing traditional stationary brick-and-mortar stores to mobile pop-up stores. Employing a simulation-based optimization approach rooted in agent-based simulation modeling and machine learning, we focus on exploring different scenarios to evaluate the potential of such channels. To this end, an agent-based simulation model is used to model the product diffusion process, and regression models are used to optimize store locations by predicting the most lucrative locations. Our exploration highlights how combining agent-based simulation modeling and machine learning methodologies can facilitate insights into new business models and provide decision support for retailers as well as MSMEs. Furthermore, our study elucidates how enhancing access through the use of mobile stores influences the early stages of product diffusion.
- Fair player pairings at chess tournaments Hide
-
Fair player pairings at chess tournaments
Agnes Cseh
- Flow-Designs Models for Supply Chains Hide
-
Flow-Designs Models for Supply Chains
Dominik Kamp, Jörg Rambau
- Fluid Ontologies of Contestation Hide
-
Fluid Ontologies of Contestation
Beatrice Kanyi, Mirco Schoenfeld
Stance detection is an opinion mining paradigm for various social and political applications that intends to establish from a piece of text whether the author of that text is in favor of, against or neutral towards a certain subject matter. A stance is an expression of an author’s standpoint and judgement towards given propositions. Therefore, the main concern of stance detection is to study the author’s viewpoint through their written text. Stance has been used in various research as a means to linguistic forms and social identities that have the capability to better understand the background of persons with stances divided into completely opposing groups. Stance detection does not focus on understanding the reasons behind a stance. This work aims to investigate how online and offline dynamics relate to one another and how to produce knowledge about these, specifically in the context of Burkina Faso. The interdisciplinary approach cultivated here, helps to uncover insights and patterns as well as highlight possible connections within a large dataset obtained from the social spheres of Burkina Faso. We assimilate a motif-based method for standpoint identification in our dataset. The opinions conveyed in social media messages played a significant role in the success of the 2014 uprisings that happened in the country against the then president Blaise Compaore, hence the technique proposed above. As a valuable NLP tool, stance detection helps gauge the presence of alignment or the lack thereof within textual content such as comments and posts extracted from mainly facebook and various Burkina-based news sites such as lefaso.net. Since stance detection is a target-reliant task, the disposition and orientation of an individual’s opinion arising from the statements, expressions and linguistic constitution of their post or comment further contributes to the prediction that is made of whether the text expresses a neutral, favor or against stance taking into account a particular target. Our work in its multifaceted nature aims to fulfil an inquisition for knowledge that will help gain a deeper understanding into the political dynamics of Burkina.
- Graph Pattern Matching in GQL and SQL/PGQ Hide
-
Graph Pattern Matching in GQL and SQL/PGQ
Wim Martens, et al.
As graph databases become widespread, JTC1—the committee in joint charge of information technology standards for the Interna- tional Organization for Standardization (ISO), and International Electrotechnical Commission (IEC)—has approved a project to cre- ate GQL, a standard property graph query language. This comple- ments a project to extend SQL with a new part, SQL/PGQ, which specifies how to define graph views over a SQL tabular schema, and to run read-only queries against them.
Both projects have been assigned to the ISO/IEC JTC1 SC32 working group for Database Languages, WG3, which continues to maintain and enhance SQL as a whole. This common responsibility helps enforce a policy that the identical core of both PGQ and GQL is a graph pattern matching sub-language, here termed GPML.
The WG3 design process is also analyzed by an academic working group, part of the Linked Data Benchmark Council (LDBC), whose task is to produce a formal semantics of these graph data languages, which complements their standard specifications.
This paper, written by members of WG3 and LDBC, presents the key elements of the GPML of SQL/PGQ and GQL in advance of the publication of these new standards.
- Human-AI Interaction in Writing Tools Hide
-
Human-AI Interaction in Writing Tools
Daniel Buschek, Hai Dang, Florian Lehman
This poster provides an overview of our research on interactive applications for working with digital text documents. Based on a set of empirical studies with prototype software developed in our group, we share insights into the opportunities and challenges of using AI to augment human writing, editing and text-based communication. This work demonstrates a range of methods and measures within a user-centred design and research approach, from quantitative analysis of human behaviour in interaction, to qualitative insights from observations and interviews with writers and other relevant user groups. Together, our findings shed light on the effect of (generative) AI on writing and writers themselves. Finally, we critically reflect on what to automate in knowledge work - and what not - considering that, in many cases, humans write not only to "get text". We write to think.
- Informal settlements in urban areas Hide
-
Informal settlements in urban areas
Franz Okyere, Meng Lu
We want to gain insight into the changes that occur in urban areas where informal settlements are formed. With the advent of remote sensing platforms and Very High Resolution(VHR) imagery, the possibilities are not limited to a visual interpretation of features shown in the imagery but other intuitive methods can be applied to reveal more information about the urban structure.
The motivation of the study lies in the occurrence of events leading to the destruction or reconstruction of structures at specific time stamps. This evidence can be found in media releases. The planned interventions are also documented by the local municipal authority. Since studies on the extraction of features that define slum environments have focused on underdeveloped countries or developing countries, there could be a need for a closer look at any point in time. This is because slums cause severe societal problems and are characteristic of deprivation regions.
In this study, we will employ existing deep learning models and techniques and investigate the possibility of selecting optimal statistical learning methods with one objective in mind. It is an aspect of artificial intelligence requiring the training of a model and subsequent prediction of the labels. The use of statistical learning methods for object detection is useful and we can apply them to our study area to understand the changes that have occurred over time.
The morphology of slums can be measured and that can serve as a check on the detection capability of the deep learning model. Slums are unique in terms of population density, spatial complexity, heterogeneity and even the ontologies. Prior studies have made attempts to contribute to the detection and delineation of these informal settlements by applying deep learning. The study will relate the presence of slum buildings in parts of the city of Accra, Ghana to deprivation. This can be achieved by segmenting the satellite imagery using remotely sensed methods together with socio-economic data. Changes that have occurred between 2017 and 2023 can then be studied to reveal new knowledge. We will apply statistical learning specifically to very high-resolution (VHR) remote sensing imagery and extract features. Additionally, high-resolution imagery can be used for the detection of slums. We hope to effectively extract the outline of slum building outlines and other slum features of the slum environment. We can then establish a relationship between spatial heterogeneity, morphology and urban poverty and test across other cities to determine whether poverty exists in these areas.
Keywords: Slum mapping, Remote sensing, Geographical information systems, Morphology, Deep learning
- Improving polymer property predictions using knowledge transfer from molecules to polymers Hide
-
Improving polymer property predictions using knowledge transfer from molecules to polymers
Nikita Agrawal, Christopher Künneth
In polymer informatics, the availability of high-quality structured data for training machine learning models to predict polymer properties is a crucial problem. Transferring knowledge from the data-rich molecule domain to polymers using deep neural networks is a promising avenue for overcoming this data scarcity. In this project, we utilised different transfer learning techniques such as zero-shot learning, few-shot learning, fine-tuning, and frozen featurization to improve the prediction accuracy of the polymer band gap that determines the material's electrical conductivity and optical properties.
We develop base machine learning models for molecules and polymers using three different fingerprinting techniques that numerically encode the polymers, namely Circular, PolyBERT, and MiniLM fingerprints. The models for molecules serve as a starting point for training the transfer learning models, while the base models for polymers allow us to validate the performance improvements of our transfer learning approaches. We find that zero-shot and few-shot learning from molecules to polymers does not improve the prediction accuracy for the band gap, because the difference between molecules and polymers cannot be learned in no or few epochs. On the contrary, the fine-tuning and frozen featurization transfer learning models show significant improvements in the prediction accuracy of the band gap. We conclude that retaining a few layers in frozen featurization or fine-tuning allows for learning the differences as well as similarities between the molecule and polymer domains.
- Integrated and Contextualized Research Data Management at the Cluster of Excellence Africa Multiple Hide
-
Integrated and Contextualized Research Data Management at the Cluster of Excellence Africa Multiple
Mirco Schoenfeld, Cyrus Samimi
In order to support the transdiscilplinary and geographically distributed research underway in the African Studies, it is the Cluster of Excellence Africa Multiple's aim to establish a system for Research Data Management (RDM) that fosters best practices in data collection, sharing, and discovery. RDM has become a cornerstone of scientific effort and collaboration, providing researchers with tools for creating, editing, and sharing relevant data objects; an observation often echoed in funding bodies' requirement for RDM-concepts as part of the grant proposal.
Thus, a solid concept for RDM can be considered good scientific practice, as it not only fosters collaboration across scientific fields and timezones, but also contributes to the longevity of research results by providing means for centralized backups.
As such, we present our efforts to establish a Digital Research Environment (DRE) at the Cluster of Excellence Africa Multiple, specifically WissKI (Wissenschaftliche Kommunikationsinfrastruktur, "scientific communication-infrastructure"), the system where research data is collected and new interconnections between data items can be determined programmatically.
WissKI harvests metadata from various repositories, such as those established by the African Cluster Centers (ACCs). As such, WissKI aggregates the data's description, whereas the data itself remains local to the institution housing it. This approach facilitates drawing connections between geographically disparate data items, while not reclaiming ownership.
Building on the open-source framework Drupal, WissKI remains modular and extensible. To arrive at a Digital Research Environment that reveals novel inter- and transdisciplinary interconnections between researchers, we will extend WissKI's core functionality with custom modules that support contextualized recommendations and user-centric search capabilities. By setting communities and individuals that contribute to and use WissKI as the focal point for our development, we aim to establish a system of fluid ontologies in which the items' exposition is not only determined by central institutions, but emerges from users' interaction.
- Interactive Learning Enhancement through AI-supported Quizzes Hide
-
Interactive Learning Enhancement through AI-supported Quizzes
Enes Gümüssoy, Manuela Floßmann, Fabian Feselmayer, Julian Fröstl, Johannes Praml, Felix Hädrich, Lukas da Silva Lorenz
As part of the project:
KI-Tutor:innen Bavaria
The initiative "KI-Tutor:innen Bayern", led by ProLehre at the Technical University of Munich and the ZHL, aims to integrate Artificial Intelligence harmoniously and beneficially into teaching and learning processes. With the involvement of 50 AI tutors from various Bavarian universities, the aim is to optimize teaching and learning methods through the use of the latest AI technologies, while at the same time creating a framework that minimizes potential dangers.
The integration of Artificial Intelligence (AI) in university education represents a significant paradigm shift, offering innovative approaches to enhance the teaching and learning experience. Central to this transformation is the use of AI-supported quizzes, which are not only a tool for assessment but also a means to actively engage students in the educational process. These quizzes are designed to adapt to the individual learning needs and progress of each student, thus providing a personalized learning experience that fosters a deeper understanding of the course material. This initiative also involves the development of an AI-based evaluation program. This program aims to revolutionize the way student performance is assessed by automating the grading process. This automation ensures a quick, efficient, and, most importantly, objective evaluation of quiz responses and overall student performance. The design of this system is in strict compliance with university standards and examination requirements, guaranteeing a fair and transparent assessment process.
Moreover, the program is equipped to provide detailed, constructive feedback to students. This feedback is crucial for recognizing learning progress and offering targeted suggestions for improvement, thereby supporting the overall educational journey of the students. The interdisciplinary integration of AI technologies across various teaching areas is also a focal point of this initiative. By embedding these technologies in different subjects, we aim to enrich a broad spectrum of academic disciplines and foster the digital transformation in education
- JSXGraph - Mathematical visualization in the web browser Hide
-
JSXGraph - Mathematical visualization in the web browser
Matthias Ehmann, Carsten Miller, Volker Ulm, Andreas Walter, Alfred Wassermann
JSXGraph (https://jsxgraph.org) is a cross-browser JavaScript library for interactive geometry, curve plotting, charting, and data visualization in the web browser. It is developed as an open source project at the Chair of Mathematics and Didactics and the "Center for Mobile Learning with Digital Technology" at the University of Bayreuth since 2008. JSXGraph applications run in every web browser on smartphones, tablets or desktop computers, as well as in ebooks (e.g. mdbook, epub3, ibook). JSXGraph is double licensed with LGPL and MIT, its download size is a mere 200 kByte.
A selection of JSXGraph features are: plotting of function graphs, curves, implicit curves, vector fields and Riemann sums; support of various spline/interpolation types and Bezier curves; the library comes with differential equation solvers, nonlinear optimization, advanced root finding, symbolic differentiation and simplification of mathematical expressions, interval arithmetics, projective transformations, path clipping as well as some statistical methods. Further, (dynamic) mathematical typesetting via MathJax or KaTeX and video embedding is supported. Up to now, the focus was on 2D graphics, 3D support using wireframe models has been started recently.
A key feature of JSXGraph is its seamless integration into web pages. Therefore it became an integral part of several e-assessment platforms, e.g. the moodle-based system STACK, which is very popular for e-assessment in "Mathematics for engineering" courses worldwide. The JSXGraph filter for the elearning system Moodle is meanwhile available in the huge Moodle installation "mebis" for all Bavarian schools, as well as in elearning platforms of many German universities, e.g. University of Bayreuth and RWTH Aachen. A recent estimate is that JSXGraph applications are downloaded by web browsers approximately 1 billion times per year. The JSXGraph development team has been / is part of several EU Erasmus+ projects (COMPASS, ITEMS, Expert, IDIAM).
- KI-Tutorinnen an der Uni Bayreuth Hide
-
KI-Tutorinnen an der Uni Bayreuth
Furkan Babuscu
- Land cover classification based on open-source satellite imagery using Unet Hide
-
Land cover classification based on open-source satellite imagery using Unet
Lindes De Waal, Christopher Shatto, Vincent Wilkens, Frank Weiser, Carl Beierkuhnlein
Land cover classifications (LCC) are a fundamental component to mapping natural landscapes and aid in resource management, land use decisions and monitoring change to ecosystems. Most LCCs today are created at the regional- and national-levels based on satellite imagery using machine learning approaches such as Support Vector Machines (SVM), Random Forests (RF) and other neural networks. Beyond computational requirements, the challenge of yielding accurate and realistic LCCs can largely be attributed to the spatial resolution of the imagery used, with open-source multispectral platforms typically known for having too coarse of spatial resolution for delineating distinct ecosystem borders and transition zones. While deep learning methods have advanced in recent years, within the field of Earth Observation and Remote Sensing their usage is often rooted in object detection and pixel-based segmentation of smaller, localized study areas. Here, we seek to improve LCCs on the island of La Palma in the Canary Islands, Spain where vegetation maps have traditionally been amended by local botanists and ecologists. Using open-source satellite imagery from Planet, we train and test a U-Net model to classify the three main forest types on La Palma: pine, laurel and fayal brezal. We compare these results with the output of a trained Random Forest model and existing LCC maps of the island. Our results highlight the growing utility of deep learning models for improving the accuracy of land cover classifications of natural ecosystems for use anywhere on the globe and in addressing novel ecological research frontiers.
- Lecture series for students on the use of AI Hide
-
Lecture series for students on the use of AI
Alexa Gragnato, Josephine Gärk, Salomé Kalessi, Johannes Praml, Benjamin Hahn, Claudius Budcke
- Machine Learning & Virtual Reality in (Photo)Biochemistry Research and Teaching Hide
-
Machine Learning & Virtual Reality in (Photo)Biochemistry Research and Teaching
Ulrich Krauss
The Krauss Lab (Vertretungsprofessur, Biochemistry I, Faculty of Biology, Chemistry & Earth Sciences) focuses on microbiology, molecular biophysics, protein engineering and biochemistry. Our research aims at understanding and applying the principles governing the interplay between light and biological matter, with a particular emphasis on the structure, function and applications of photoreceptors. We study biological systems across multiple levels of complexity and timescales, from picoseconds to days, and from atomistic detail to cellular function. Inspired by nature, we use this knowledge to engineer proteins with novel/improved functions.
In terms of teaching, our curriculum covers fundamental biochemical processes, general enzymology, signal transduction, protein structure/function and biochemical methods as part of the UBT B. Sc. Biochemistry programme. Two recent projects, outlined in the present contribution, showcase our use of digital methods for research and teaching.
Research: Light, oxygen, voltage (LOV) photoreceptor domains, both natural and engineered, are widely used in the design of fluorescent reporters, optogenetic tools and photosensitizers to visualize and control biological processes. In collaboration with the Mehdi Davari (Computational Chemistry, Leibniz Institute of Plant Biochemistry, Halle), we have recently addressed challenges of engineering the kinetic properties of LOV domains through machine learning (ML)-assisted protein engineering [1]. We used ML trained on literature data and iteratively generated experimental data to design LOV variants with selectively altered kinetic properties, yielding variants with kinetic time constants spanning seven orders of magnitude, thus, demonstrating the efficacy of ML to guide protein engineering even in the absence of a mechanistic model and with limited starting data.
Teaching: In distance learning settings like web conferences, reduced social presence often hampers teacher-student interaction and learning outcomes. Additionally, conveying three-dimensional content, crucial in biology and biochemistry, through two-dimensional media poses challenges in both presence and distance teaching formats. In 2022/2023, as part of a teaching innovation, we explored collaborative virtual reality (VR) to enhance social presence and interactions in distance learning, and tested the use of collaborative VR experiences in face-to-face teaching to convey three-dimensional content, using protein structure information as a test case [2].
[1] Hemmer S., Siedhoff N.R., Werner S., Ölcücü G., Schwaneberg U., Jaeger K.-E., Davari M.D., Krauss U., 2023. Machine Learning-Assisted Engineering of Light, Oxygen, Voltage Photoreceptor Adduct Lifetime. JACS AU. https://doi.org/10.1021/jacsau.3c00440
[2] Project Blog at HHU Düsseldorf: https://blogs.phil.hhu.de/xr4edu/; ResearchGate Interview: https://shorturl.at/itxPS
- Measuring technology acceptance over time based on online customer reviews and transfer learning Hide
-
Measuring technology acceptance over time based on online customer reviews and transfer learning
Daniel Baier, Andreas Karasenko, Alexandra Rese
Online customer reviews (OCRs) are user-generated semi-formal evaluations of products, services, and/or technologies. They typically consist of a time stamp, a star rating, and – in many cases – a natural language comment that reflects acceptance, strengths, and weaknesses as perceived by the evaluator. OCRs are easily accessible on the internet in large numbers, e.g. via review sites, app stores, electronic market places and/or online shops. In this research project, we propose a new transformer-based transfer learning approach that allows to predict extended technology acceptance model (TAM) construct scores from OCRs. We train, test, and validate this approach using large samples of OCRs together with corresponding construct scores derived from surveys with experts and customers. From a managerial point of view, the new approach goes beyond traditional acceptance measurement since it allows to discuss the temporal development of product, service, and/or technology acceptance and possible improvements.
- Monitoring of Additive Manufacturing with infrared imaging and prediction of the tensile strength with Machine Learning Hide
-
Monitoring of Additive Manufacturing with infrared imaging and prediction of the tensile strength with Machine Learning
Niklas Bauriedel, Julia Utz, Rodrigo Albuquerque, Nico Geis, Holger Ruckdäschel
Additive Manufacturing (better known as 3D-prinitng) is a promising technology that will be used more and more in the future. However, the quality of the manufactured components and their monitoring is a major problem that is still preventing the use of this technology. Temperatures are an important factor influencing the results of the well-known Fused Filament Fabrication. Infrared cameras are used to monitor this process. The data obtained is analyzed and used with the help of Machine Learning techniques. A model was created to predict the tensile strength of a finished component based on the measured material temperature values on each printed layer. This allows statements to be made about the mechanical properties of a finished component and therefore also about the quality of the component.
- National Research Data Infrastructure for and with Computer Science (NFDIxCS) Hide
-
National Research Data Infrastructure for and with Computer Science (NFDIxCS)
Agnes Koschmider, Melanie Scholz
The main goal of the project NFDIxCS is to identify, define and finally deploy services to store complex domain specific data objects from the specific variety of sub-domains from Computer Science (CS) and to realize the FAIR principles across the board. This includes to produce re-usable data objects specific to the various types of CS data, which contain not only this data along with the related metadata, but also the corresponding software, context and execution information in a standardized way. The key principle in NFDIxCS is to assemble an organizational and technical, cooperative and interoperable infrastructure to join the available forces of relevant services and actors from and for CS.
The Process Analytics research group@UBT will design techniques for semantic data management and the association of data with FAIR principles. First, we will evaluate entities, relationships, functions and axioms hold for all sub-disciplines and will define and formalize an upper ontology. The formalized model will be implemented in an ontology language. Next, the ontology will be used as a schema layer for a knowledge graph. Finally, metadata will be used to validate the designed techniques. Metadata will be standardized in terms of an ontology with unique identifiers.
- Navigating the Maze of Wikidata Query Logs Hide
-
Navigating the Maze of Wikidata Query Logs
Angela Bonifati, Wim Martens, Thomas Timm
We provide an in-depth and diversified analysis of the Wikidata query logs, recently made publicly available. Although the usage of Wikidata queries has been the object of recent studies, our analysis of the query traffic reveals interesting and unforeseen findings concerning the usage, types of recursion, and the shape classification of complex recursive queries. Wikidata specific features combined with recursion let us identify a significant subset of the entire corpus that can be used by the community for further assessment. We considered and analyzed the queries across many different dimensions, such as the robotic and organic queries, the presence/absence of constants along with the correctly executed and timed out queries. A further investigation that we pursue in this paper is to find, given a query, a number of queries structurally similar to the given query. We provide a thorough characterization of the queries in terms of their expressive power, their topological structure and shape, along with a deeper understanding of the us- age of recursion in these logs. We make the code for the analysis available as open source.
- Non-invasively decoding of the neural drive in the upper-limb during individual finger movements Hide
-
Non-invasively decoding of the neural drive in the upper-limb during individual finger movements
Renato Mio
Advancements in recording methods for neurophysiological signals, in particular, the use of high-density surface electromyography (HD-sEMG) results in increased spatial resolution but also opens the possibility to decode the neural drive to muscles. The higher number of electrode channels allows the detection of individual motoneuron action potentials and spike trains through the technique known as motor unit (MU) decomposition. Current studies on decomposition for decoding the neural drive to muscles focus on lower limb muscles, where the number of decoded MUs can be much higher compared to upper limb muscles [1]. This is mainly due to anatomical differences affecting signal propagation. Regardless, MU decomposition in the upper limb opens the exciting possibility to non-invasively decode the neural drive during manipulation tasks that involve a richer motor repertoire. Hence, in this study, neural drive decoded through motor unit decomposition from forearm muscles during finger movement is analysed. We decided to analyse the neural drive during individual finger movement as a starting point before moving to multi-finger gestures.
For this study, a publicly available dataset (the Hyser MVC dataset [2]) of HD-sEMG over forearm muscles during individual finger flexion and extension were analysed. The dataset comprises 256 EMG channels over the forearm flexor and extensor muscles (128 on each side of the forearm) during individual finger isometric contractions. Automatic motor unit decomposition was applied to this dataset using the method by Negro et al. [3]. The decomposition hyperparameters were chosen after empirical testing in sub-samples of the dataset to ensure reliable identification of MUs. We extracted the number of decomposed MU, their locations, and their waveforms’ amplitudes over the electrode grid.
On average, 6.22 ± 9.47 (n=20) MUs were decomposed from anterior forearm muscles during finger flexions and 3.46 ± 3.54 (n=20) from the posterior forearm during finger extensions, with 128 channels on each side. There was a very high inter-subject variability on the number of decoded MUs (see Fig. 1). Despite this, there were clear areas where the MU activations where clustered depending on which finger was flexing or extending (see Fig. 2 and Fig. 3). To verify this, the mean cosine similarities of the activation maps across participants and for each finger were computed, resulting in a grand average of 0.91 ± 0.03.
From these results, we can infer that, although the number of MUs decoded in forearm muscles is lower than what can be expected from lower limb muscles, more MUs could be decoded from specific subjects, which might be related to variable signal recording quality across sessions. Nonetheless, MU activity was clustered over specific finger-dependent areas, and this was consistent across subjects. Therefore, for isometric contractions, it is possible to consistently decode neural drives with similar spatial distributions for each individual finger movement with low inter-subject variability. This is crucial for non-invasive interfaces decoding neural drive that require increased selectivity. Additionally, knowledge of this activation areas could be used to apply moderate ablations by removing the less active electrodes depending on the movement studied, thus improving computation times.
- Optimal Feedback Control with Neural Networks Hide
-
Optimal Feedback Control with Neural Networks
Mario Sperl, Lars Grüne
We discuss the use of neural networks for solving optimal control problems, that is we want to minimize a cost function with respect to some given dynamics. Such problems occur in many applications, e.g., power systems, robotics and autonomous driving. While grid- or mesh-based numerical methods suffer from an exponential growth of the numerical effort in the number of variables, neural networks are capable of overcoming this so-called curse of dimensionality under certain conditions. We identify such suitable conditions that allow neural networks to efficiently solve optimal control problems. Moreover, we construct a neural network architecture and a corresponding training algorithm. We illustrate the training process with a numerical test case.
- Process Analytics Pipeline for Unstructured Data Hide
-
Process Analytics Pipeline for Unstructured Data
Agnes Koschmider, Christian Imenkamp, Dominik Janssen, Dominic Langhammer, Melanie Scholz, Yorck Zisgen
Disciplines like engineering, life and natural sciences have a high demand for efficient data analytics. Their main purpose is to get new insights into data and in this way to complement traditional techniques like computer simulation.
The Process Analytics research group@UBT develops theoretical concepts for efficient processing and analysis of unstructured data (e.g., sensor event data, time series and video data). The techniques are validated using software prototypes. Particularly, the research group designs concepts for the extraction of cause-effect chains in data with the aim of providing new insights into the data through data-driven approaches and AI methods. The data analysis focuses on sensor event data, time series and video-based data, and are intended identifying outliers or making predictions. The application scenarios have a wide focus and range from sensor event data in medical applications and smart home, time series from geography or multibeam data from marine science. Usually there is a matter of data quality in the application domains. To bridge the gap, the research group develops a tool for synthetic data.
To sum up, our research interest broadly explores:
• How to design a framework for the efficient processing of low-level data allowing to extract process knowledge?
• How can machine learning be used to increase data quality (e.g. outlier) and thus accelerate data and process analysis?
• How can synthetic data be efficiently generated that enable privacy-awareness or distributed analysis?
• How can machine learning be used to reduce the involvement of users, but to increase the quality of the data-driven, discovered processes?
We are involved in several third-party funded projects and are open to (interdisciplinary) collaboration. The purpose of our poster would be to present our latest research results.
- Process monitoring, control and error analysis through knowledge-based modelling of production processes using Bayesian networks Hide
-

Process monitoring, control and error analysis through knowledge-based modelling of production processes using Bayesian networks
Jonas Krauss
The shortage of skilled workers is also affecting the plastics industry - together with the German Plastics Centre (SKZ), Fraunhofer IPA is developing digital quality models for the injection moulding process. These are designed to generate recommendations for action based on real-time data and make the work of plant operators easier in the future. Based on expert knowledge, simulation data and measurements of real injection moulding processes, Bayesian networks are being developed for quality prediction and fault diagnosis. Thanks to bidirectional inference mechanisms, Bayesian networks can both predict the quality of the moulded part based on process parameters and diagnose the causes of quality deviations. The topology of the network is defined in expert workshops based on the prevailing cause-effect relationships. This is then quantified using the available data. By transparently linking expert knowledge with data, the Bayesian network is not subject to the typical black-box problems of other AI methods, and the decision-making process is comprehensible to experts. The active involvement of application partners from industry ensures the practicality of the methodology and the transferability of the models to real processes and data.
- Regulating the digital transformation of the agrifood sector—an innovation systems perspective Hide
-
Regulating the digital transformation of the agrifood sector—an innovation systems perspective
Tilman Reinhardt
The digital transformation of the European agrifood sector is in full swing. While some technologies have been around for decades, and diffusion has initially been slower than expectations, there now appears to be a renewed and self-sustaining push to digitalize all levels of the food value chain. The digital transformation, however, is not just an inevitable fact. Tt is also the “best hope” for achieving sustainability in food production. Digital technologies are seen as key solutions to bridge the gap between productivity and sustainability. They are also a key “enabling technology” for many other potential game changers, especially biotechnology. We assess how the evolving European regulatory framework, especially the Farm to Fork (F2F) strategy, affects the development of the innovation system for digital farming using the Technological Innovation Systems framework. We show that the F2F strategy contributes to innovation system performance by providing a clear and coherent agenda and various concrete measures designed to support innovation, knowledge and skill development. However, it falls short in creating favorable market conditions for innovative technologies and building legitimacy with farmers as the most important user group.
- Risks Deriving from the Agential Profiles of Modern AI Systems Hide
-
Risks Deriving from the Agential Profiles of Modern AI Systems
Barnaby Crook
Modern AI systems process large volumes of information to learn complex representations that support goal-directed behaviours (LeCun et al., 2015). This makes them markedly more agential than traditional tools. At the same time, such systems lack critical aspects of biological agency such as embodiment, animacy, and self-maintenance, thus distinguishing them from living organisms (Moreno & Etxeberria, 2005). In this paper, I argue that this combination of properties creates a challenge for categorising and reasoning about modern AI systems, and that this challenge plays a role in explaining their potential to subvert human goals. In particular, modern AI systems combine 1) an almost total absence of the superficial features which ordinarily allow us to recognise the presence of adversarial agents, and 2) sophisticated information processing capabilities which support goal-directed behaviour. This distinctive agential profile can be dangerous when AI systems pursue goals incompatible with our own in a shared environment (Russell & Norvig, 2020). Highlighting the increase of damaging outcomes such as digital addiction (Meng et al., 2022), I argue that the agential profiles of modern AI systems play a crucial and underappreciated role in explaining how and why they produce harms.
I suggest an AI system’s agential profile plays a crucial role in explaining a subject’s maladaptive habitual behaviour when the following conditions are met. First, the subject displays maladaptive habitual behaviour (i.e., engages in habitual behaviour which consistently undermines their higher-order goals) (Bayer et al., 2022). Second, the AI system behaves as though it is maximising a performance measure whose value depends on the subject’s behaviour (Russell & Norvig, 2020). Third, the maximisation of that performance measure depends upon the subject behaving in ways incompatible with that subject’s own higher-order goals (Franklin et al., 2022). Fourth, the agential properties of the AI system make a (significant) difference to its capacity to induce the habitual behaviours in question. Fifth, the difficulty of recognising the agential properties of the AI system makes a difference to its capacity to induce the habitual behaviours in question.
If the argument above is correct, modern AI systems’ agential profiles are crucial to explaining why they are liable to subvert human goals. Such explanations do not compete with, but augment explanations of maladaptive habit formation in terms of the brain mechanisms of habit formation (e.g., Serenko & Turel, 2022). Though I present theoretical reasons supporting the plausibility of my argument, empirical work is needed to assess whether and to what degree it holds in practice. If my claims are borne out empirically, there are implications for ameliorative policies. For example, cues indicating that one is interacting with a system with a particular agential profile could induce more mindful and prudential behaviour, limiting the danger of maladaptive habit formation. In the longer term, assuming society continues to produce and deploy AI systems with unfamiliar agential profiles, refinement of our collective conceptual understanding through education may be required to protect human values from further risks.
- sketchometry 2.0 - innovative human-computer interaction Hide
-
sketchometry 2.0 - innovative human-computer interaction
Matthias Ehmann, Carsten Miller, Volker Ulm, Andreas Walter, Alfred Wassermann
sketchometry (https://sketchometry.org) is a digital mathematics notebook application for highschools, i.e. it is an interactive construction and exploration tool for plane Euclidean geometry and calculus. Since it is aimed to be used mainly on smartphones and tablets, sketchometry introduces innovative strategies for human-computer interaction in learning software. Basic elements like points, circles and lines can be sketched on the screen with fingers, mouse or pen. More complex operations like bisecting angles or constructing perpendicular lines can be achieved with intuitive gestures. sketchometry identifies these sketches and gestures with a machine-learning approach and generates an exact figure. This allows the students to explore these constructions in a very natural way by dragging, rotating and manipulating the geometric objects.
sketchometry is developed at the Chair of Mathematics and Didactics and the "Center for Mobile Learning with Digital Technology" at the University of Bayreuth. It is free to use, runs on all smartphones, tablets or desktop computers. It can be used with every web browser, app versions are available for Android and iOS. A preview of the upcoming spectacular sketchometry 2.0 is available at https://sketchometry.org/beta. The new version comes with a much improved user experience on small mobile devices. The official release date will be in February 2024.
sketchometry is implemented in JavaScript, visualization is done with our own library JSXGraph (https://jsxgraph.org). It runs on client side, no online connection is necessary. This means, the sketch recognition is completely done using the limited computational resources of the web client without communication to any server. The mathematics behind this approach consists of computation of angles in a high-dimensional space and an efficient corner-finding algorithm.
- Solve Ax=b with 0/1 variables Hide
-
Solve Ax=b with 0/1 variables
Alfred Wassermann
Finding 0/1 solutions for a system of linear equations Ax=b, where A is an integer matrix and b is an integer vector, is a well-known NP-complete problem with many applications, e.g. in combinatorics, coding theory, and cryptography. In fact, it is one version of integer linear programming. There are many practical algorithms available to solve this problem, for example integer linear programming solvers like CPLEX and Gurobi, backtracking algorithms like "dancing links", or SAT solvers.
For specific instances where the vector b consists of large integers, and also in cases where A has integer entries of mixed signs, the author's program "solvediophant" seems to be faster than other approaches. With it's help many new combinatorial objects and new record-breaking error-correcting codes have been constructed.
The algorithm is based on lattice basis reduction and exhaustive enumeration of points in a high dimensional lattice. Additionally, solvediophant can be used with a non-standard backtracking approach called "least discrepancy search" which seems to be especially well suited for LLL-reduced lattice bases.
solvediophant solves instances up to 1500 variables and can be used not only for 0/1 variables but also for integer variables in a finite interval.
- SOURCED – Process Mining on Distributed Event Sources Hide
-
SOURCED – Process Mining on Distributed Event Sources
Christian Imenkamp
SOURCED is a research unit focused on developing new approaches for distributed, online process mining on sourced event data. SOURCED is a team of researchers from various institutions and aims to address technical and conceptual research challenges in this domain.
One of the key components of the project is the Tiny house real-world laboratory. This laboratory will serve as a prototype for realistic experimental studies. Equipped with various sensors and devices, the Tiny house will generate and collect sensor data. This real-world data will be used to evaluate the developed process mining techniques in a practical setting. Additionally, the Tiny house will be open to the broader research community, providing a platform for conducting experiments and evaluating process mining techniques in a real-world context.
AI (Artificial Intelligence) is an important component of SOURCED. It has the potential to enhance the project's ability to analyze and process large amounts of data. Additionally, the use of AI techniques, such as machine learning and deep neural networks, can be used to gain insights into complex relationships between events. AI can help the project to identify patterns and anomalies in the data, which can be used to improve the accuracy and efficiency of the process mining techniques being developed. As the project continues to evolve, AI will become an increasingly important tool for analyzing the vast amounts of data generated by distributed event sources.
Overall, SOURCED's focus on distributed, online process mining and its utilization of the Tiny house real-world laboratory represent innovative and practical approaches to addressing the challenges of process mining in real-world, distributed environments.
- The element of surprise: knowledge-informed recommendations Hide
-
The element of surprise: knowledge-informed recommendations
Oliver Baumann, Durgesh Nandini, Anderson Rossanez, Mirco Schoenfeld, Julio Cesar dos Reis
Recommender systems for large catalogs of multimedia content have become an important asset in the information retrieval toolkit. Recommendations can expose users to relevant items and expand their understanding of the collection as a whole, regardless if in an e-commerce-, media-streaming-, or GLAM-setting (Galleries, Libraries, Archives, Museums).
Popular approaches for determining candidate items for recommendations are content-based and collaborative filtering algorithms, as well as hybrid systems. In content-based filtering, item characteristics are used to determine similarity between items rated (viewed, listened, bought, etc.) by a user, and “unseen” items. Collaborative filtering, on the other hand, determines users similar to the target user, and predicts ratings on unseen items by the target user.
While these approaches have been shown to produce meaningful recommendations, the items they recommend tend to be expectable and located in whatever portion of the catalog is considered “mainstream”. Furthermore, these approaches do not take into account the rich relations that may exist between items, beyond the realm of similarity alone. For instance, a user may be intrigued by a movie that features music they listen to, or a book authored by their favourite actor. These relations are well represented by knowledge graphs, in which vertices represent the items, or “entities”, and edges the relations they form. Knowledge graphs (KG) have previously been used successfully in recommender systems.
In our work, we explore to which extent KG-based recommender systems can provide an element of surprise in their output. Surprise is strongly related to the notion of serendipity: discovering relevant facts “by a happy accident”. Serendipitous recommendations may get users in touch with items they have so far been unaware of, but nevertheless are relevant to their interests.
Specifically, we explore how graph measures can be applied to gauge the level of surprise recommended items provide to a user’s profile. We analyse how measures such as network diameter, subgraph modularity, and various centrality metrics behave under the inclusion of state-of-the-art recommendations into the user’s profile-subgraph, and propose a system that identifies surprising items by maximising or minimizing these metrics.
- User-centric query disambiguation Hide
-
User-centric query disambiguation
Oliver Baumann, Mirco Schoenfeld
Querying for and locating relevant items in large information systems is hard, especially if the query exhibits multiple senses that may relate to different corpus items. For example, a search for "Amazon" may resolve to the river, the rainforest, the company, or the mythical women warriors. However, without further context, a search engine is unable to perform the correct word-sense disambiguation to surface the item most relevant to the user. We argue that Personalized Query Expansion (PQE) can provide the desired disambiguation by expanding a given query with semantically similar terms in the context individual users. PQE has been studied previously for its ability to lessen the impact of query-document vocabulary mismatch that occurs when a user's query exhibits language that does not match with relevant documents due to, e.g., synonym terms. However, PQE's effect on disambiguation is not well studied.
In our work, we aim to better understand PQE's properties with regards to disambiguating short queries. We construct language models using word2vec for a set of synthetically generated user profiles, and expand the original query with terms that show high semantic similarity between query and profile. We find that, for an a priori known target article, PQE is able to rank this article higher than a non-expanded query.
Additionally, PQE tends to return results that more closely match users' interests on a category-level. Thus we conclude that PQE can serve as a valuable building block in constructing information systems that respect users' previous searches, and react to their interests. We plan on implementing such a system for the Digital Research Environment developed as part of the "Africa Multiple" Cluster of Excellence at the University of Bayreuth.
- Using MILPs for creating robust adversarial examples Hide
-
Using MILPs for creating robust adversarial examples
Jörg Rambau, Rian Richter
- Why neural functionals suit statistical mechanics Hide
-
Why neural functionals suit statistical mechanics
Florian Sammüller, Sophie Hermann, Matthias Schmidt
We describe recent progress in the statistical mechanical description of many-body systems via machine learning combined with concepts from density functional theory and many-body simulations. We argue that the neural functional theory by Sammüller et al. [Proc. Nat. Acad. Sci. 120, e2312484120 (2023)] gives a functional representation of direct correlations and of thermodynamics that allows for thorough quality control and consistency checking of the involved methods of artificial intelligence. Addressing a prototypical system we here present a pedagogical application to hard core particle in one spatial dimension, where Percus’ exact solution for the free energy functional provides an unambiguous reference. A corresponding standalone numerical tutorial that demonstrates the neural functional concepts together with the underlying fundamentals of Monte Carlo simulations, classical density functional theory, machine learning, and differential programming is available online at https://github.com/sfalmo/NeuralDFT-Tutorial.
- XR-Campus at UBTHide
-
XR-Campus at UBT
Nadine Jachmann, Jonas Würdinger, Jan Staufer, Theresa Weiß, Raphaela Galler, Numrah Azhar, Kristina Keil, Annika Lelke, Leonard Rahimi, Farid Desai, Fabian Braun, Elena Rechner, Hamdi Catalpinar
As part of XRCampus, the ZHL (Centre for Teaching and Learning) at the University of Bayreuth provides 10 positions for student assistants to be trained as XR tutors. Chairs and other university institutions apply with a project idea on how XR could be used in their teaching. Each XR tutor is responsible for one individual project.
The primary aim of XRCampus is to arouse interest in the use of XR for teaching by breaking down barriers. Working with the technology initially seems complicated and reserved for experts. The core of the project is to train students who do not necessarily have any prior technical knowledge to become XR tutors. This will show how non-experts can develop XR products for everyday teaching.
A poster is to be created for each individual project to provide an overview of the interesting and diverse ways in which XR can be used in teaching.
For further information please visit: https://www.zhl.uni-bayreuth.de/de/projekte/xrcampus/index.html